[toc]
防火墙
概念
防火墙是“一台或一组设备,用以在网络间实施访问控制策略”。
防火墙既可以是软件,也可以是硬件。
防火墙管理工具
我们常说的 Linux 防火墙,包含 iptables 和 netfilter,但常用 iptables 来指代防火墙,它是三层防火墙。请注意以下管理工具是用来配置规则,真正根据规则做出过滤的是内核模块。以下列出了很多用户管理工具,主要是希望不要混淆这些东西。
iptables/ip6tables
iptables/ip6tables —— IPv4/IPv6 数据包过滤和NAT的管理工具。iptables 是用户空间命令行程序,用于配置Linux 2.4.x及以上版本的报文过滤规则集。由于网络地址转换也是从数据包过滤器规则集配置的,因此 iptables 也用于此目的。
**iptables 和 ip6tables 用于在Linux内核中设置、维护和检查 IPv4 和 IPv6 数据包过滤规则的表。**可以定义几个不同的表。每个表都包含许多内置链,也可能包含用户定义的链。每个链都是一个规则列表,这些规则可以匹配一组数据包。每个规则都指定如何处理匹配的数据包。这被称为“目标”,可能是跳转到同一表中的用户定义链。
ipset
ipset —— IP集的管理工具。ipset 是 Linux 2.4.x 及更高版本内核中的一个框架,用于在 Linux 内核中设置、维护和检查所谓的IP集。根据集的类型,IP集可能存储IP(v4/v6)地址、(TCP/UDP)端口号、IP和MAC地址对、IP地址和端口号对等,从而确保在将条目与集合匹配时达到闪电般的速度。iptables 匹配和引用集的目标创建引用,从而保护内核中的给定集。当有一个引用指向某个集时,不能销毁该集。
ipset 常与 iptables 结合使用,可以对指定集中的网络进行包过滤。
ebtables
ebtables —— 以太网桥帧表管理。ebtables 就是以太网桥防火墙,以太网桥工作在数据链路层,ebtables 主要用来过滤数据链路层数据包。ebtables 能过滤桥接流量。
arptables
artables —— ARP表管理。artables 是一个用户空间工具,用于在 Linux 内核中建立和维护 ARP 规则的表。这些规则检查他们看到的ARP 帧。arptables 类似于 iptables 用户空间工具,但arptables不那么复杂。它既能防止别的机器对自己进行 arp 欺骗,又能防止本机病毒或错误程序向其他机器发起 arp 攻击。
firewalld
firewalld 和 iptables 一样,也是一个防火墙管理工具,firewalld 管理火墙相对简单。iptables 复杂但功能强大。firewalld 是一个动态的、可定制而无需重新启动防火墙守护程序或服务。
firewalld 相比 iptables 的 2 个好处:firewalld 可以动态修改单条规则,而不需要像 iptables 那样,在修改了规则后必须得全部刷新才可以生效;firewalld 在使用上要比 iptables 人性化很多,即使不明白 “五张表五条链” ,而且对 TCP/IP协议也不理解也可以实现大部分功能。
firewalld 是 centos7 的一大特性,最大的好处有两个:支持动态更新,不用重启服务;第二个就是加入了防火墙的 “zone” 概念。
在 CentOS 8 中,nftables 取代 iptables 成为默认的Linux 网络包过滤框架。
firewall-cmd
Linux 上新用的防火墙软件,跟 iptables 差不多的工具。firewall-cmd 是 firewalld 的字符界面管理工具,
ufw
ufw —— 用于管理 netfilter 防火墙的程序。该程序用于管理 Linux 防火墙,旨在为用户提供易于使用的界面。ufw 防火墙即 uncomplicated firewall(不复杂的防火墙)是 iptables 的接口,旨在简化配置防火墙的过程,但繁琐的部分还是需要使用 iptables 进行设置。
由于 Ubuntu 系统的不断更新迭代,配置工具也发生了变化:iptables —> firewall —> ufw
fw3/fw4
OpenWRT 开发的管理防火墙的程序,fw3 基于 iptables,fw4 基于 nftables。
nft
nft —— 用于数据包过滤和分类的 nftables 框架的管理工具。
nftables 的命令行工具是 nft
nftables
nftables 取代了流行的 {ip,ip6,arp,eb}表 ,从 Linux 3.13 后可用。该软件提供了一个新的内核内数据包分类框架,该框架基于特定于网络的虚拟机 (VM) 和新的 nft 用户空间命令行工具。nftables 重用现有的 Netfilter 子系统,例如现有的钩子基础设施、连接跟踪系统、NAT、用户空间队列和日志记录子系统。
nftables是 iptables 的继任者,它允许更灵活、可扩展和更高性能的数据包分类。所有新奇的新功能都是在这里开发的。
netfilter
netfilter 项目是一个社区驱动的协作 FOSS 项目,它为 Linux 2.4.x 和更高版本的内核系列提供数据包过滤软件。这 NetFilter 项目通常与 iptables 及其后继者 NFTables 相关联。
netfilter 项目实现了数据包过滤、网络地址 [和端口] 转换 (NA[P]T)、数据包日志记录、用户空间数据包队列等 数据包篡改。
netfilter 钩子是 Linux 内核中的一个框架,它允许内核模块在 Linux 网络堆栈的不同位置注册回调函数。然后,Linux 网络协议栈中穿越相应钩子的每个数据包都会回调已注册的回调函数。
iptables 是一个通用的防火墙 允许您定义规则集的软件。IP 表中的每个规则 由多个分类器(iptables 匹配)和一个连接的操作组成 (iptables 目标)。
NFTABLES 是 iptables 的继任者,它允许更多 灵活、可扩展和高性能的数据包分类。这是所有 开发了花哨的新功能。


iptables 命令
iptables对不同的数据包处理功能使用不同的规则表。默认操作的表是filter表,非默认的表可以通过命令行中的选项指定。主要的表有三个,其他的表例如security和raw有着特殊的用途。三个主要的表分别如下:
filter表是默认的表。它包含了实际的防火墙过滤规则。其内建的规则链包括:
- INPUT
- OUTPUT
- FORWARD
nat表包含了源地址和目的地址转换以及端口转换的规则。这些规则在功能上与防火墙filter规则不同。内建的规则链包括:
- PREROUTING DNAT/REDIRECT
- OUTPUT DNAT/REDIRECT
- POSTROUTIN GSNAT/MASQUERADE
mangle表包含了设置特殊数据包路由标志的规则。这些规则接下来将在filter表中进行检查。其内建的规则链包括:
- PREROUTING 被路由的数据包
- INPUT 到达防火墙并通过PREROUTING规则链的数据包
- FORWARD 修改通过防火墙路由的数据包
- POSTROUTING 在数据包通过OUTPUT规则链之后但在离开防火墙之前修改数据包
- OUTPUT 本地生成的数据包
| Tables↓/Chains→ | PREROUTING | INPUT | FORWARD | OUTPUT | POSTROUTING |
|---|---|---|---|---|---|
| (routing decision) | ✓ | ||||
| raw | ✓ | ✓ | |||
| (connection tracking enabled) | ✓ | ✓ | |||
| mangle | ✓ | ✓ | ✓ | ✓ | ✓ |
| nat (DNAT) | ✓ | ✓ | |||
| (routing decision) | ✓ | ✓ | |||
| filter | ✓ | ✓ | ✓ | ||
| security | ✓ | ✓ | ✓ | ||
| nat (SNAT) | ✓ | ✓ |
nftables HOWTO wiki
个人机翻+修正,存在不完善之处慢慢修正
简介
1. 什么是 nftables?
nftables 是现代 Linux 内核数据包分类框架。新代码应使用它来替代传统的 {ip,ip6,arp,eb}_tables (xtables) 基础架构。对于尚未转换的现有代码库,截至 2021 年,传统的 xtables 基础架构仍将保留。自动工具可协助将 xtables 转换为 nftables。
nftables 概述
- 它在 Linux 内核 >= 3.13 中可用。
- 它带有一个新的命令行实用程序 nft,其语法与 iptables 不同。
- 它还带有一个兼容层,允许你在新的 nftables 内核框架上运行 iptables 命令。
- 它提供了一个通用的集合基础架构,允许你构建映射和关联。您可以使用这些新结构在多维树中排列规则集,从而大大减少了在对数据包采取最终行动之前需要检查的规则数量。
2. 为什么选择 nftables?
毕竟,我们喜欢 iptables,这个工具一直在为我们服务(而且在许多部署中可能还会继续服务一段时间),用于按数据包和流量过滤流量、记录可疑流量活动、执行 NAT 和许多其他功能。在过去的 15 年中,该工具提供了上百种扩展功能。
尽管如此,iptables 框架仍存在一些难以克服的局限性:
- 避免代码重复和不一致: iptables 的许多扩展都是针对特定协议的,因此没有一个统一的方法来匹配数据包字段,相反,我们为每个支持的协议都设计了一个扩展。这就使得代码库变得非常臃肿,以执行类似任务:有效载荷匹配。
- 通过增强的通用 set 和 map 基础架构加快数据包分类。
- 通过新的 inet 系列,简化了 IPv4/IPv6 双协议栈管理,允许注册同时查看 IPv4 和 IPv6 流量的基础链。
- 更好地支持动态规则集更新。
- 为第三方应用程序提供 Netlink API,就像其他 Linux 网络和 Netfilter 子系统一样。
- 解决语法不一致问题,提供更漂亮、更简洁的语法。
这些,以及其他未在此列出的内容,触发了 nftables 的开发,它最初是在法国巴黎举行的第六届 Netfilter 研讨会上向 Netfilter 社区展示的。
3. 与 iptables 的主要区别
从用户角度看,nftables 与 iptables 的一些主要区别如下:
- **nftables 使用新语法。**iptables 命令行工具使用基于 getopt_long() 的解析器,其中参数前总是有两个减号,如–key ,或一个单减号,如-p tcp。相比之下,nftables 使用的是受 tcpdump 启发的简洁语法。
- **表和链完全可配置。**iptables 有多个预定义的表和基础链,即使你只需要其中一个,所有表和基础链也都要注册。有报告称,即使是未使用的基础链也会降低性能。nftables 没有预定义的表或链。每个表都是明确定义的,只包含明确添加到其中的对象(链、集、映射、流表和有状态对象)。现在,您只需注册所需的基本链。您可以选择表和链的名称以及 netfilter 钩子的优先级,从而有效地实现特定的数据包处理管道。
- **单个 nftables 规则可执行多个操作。**与 iptables 中使用的匹配和单一目标操作不同,nftables 规则由零个或多个表达式组成,后面跟一个或多个语句。每个表达式测试数据包是否匹配特定的有效载荷字段或数据包/流元数据。多个表达式从左到右进行线性评估:如果第一个表达式匹配,则评估下一个表达式,依此类推。如果到达最后一个表达式,那么数据包就匹配了规则中的所有表达式,规则的语句就会被执行。每条语句都会执行一项操作,如设置 netfilter 标记、计算数据包、记录数据包或做出判断,如接受或丢弃数据包或跳转到另一条链。与表达式一样,多个语句从左到右进行线性评估:通过使用多个语句,一条规则可以执行多个操作。请注意,判决语句的性质是结束规则。
- **每个链和规则没有内置计数器。**在 nftables 中,计数器是可选的,你可以根据需要启用它们。
- **更好地支持动态规则集更新。**与 iptables 使用的单一 blob 不同,nftables 规则集在内部以链接列表的形式表示。现在,添加或删除一条规则后,规则集的其他部分不会受到影响,从而简化了内部状态信息的维护。
- **简化 IPv4/IPv6 双协议栈管理。**nftables inet 系列允许注册同时查看 IPv4 和 IPv6 流量的基础链。不再需要依赖脚本来复制规则集。
- **新的通用 set 基础架构。**该基础架构与 nftables 核心紧密集成,允许使用映射、判决映射和时间间隔等高级配置来实现面向性能的数据包分类。最重要的是,您可以使用任何受支持的选择器对流量进行分类。
- **支持连接。**自 Linux 内核 4.1 起,您可以将多个键连接起来,并将它们与映射和判决映射结合起来。这样做的目的是建立一个元组,对其值进行哈希处理,以获得近 O(1) 的操作。
- **无需升级内核即可支持新协议。**内核升级是一项既耗时又艰巨的任务,尤其是当你需要在网络中维护不止一个防火墙时。发行版内核通常滞后于最新版本。有了新的 nftables 虚拟机方法,支持新协议通常不需要新的内核,只需要相对简单的 nft 用户空间软件更新即可。
参考
10 分钟内快速参考 nftables
下面是使用 nftables 之前需要了解的一些基本概念。
table 是指没有特定语义的 chains 的容器。
rule 是指 chain 中要配置的操作。
1. nft 命令行
nft 是一种命令行工具,用于在用户空间与 nftables 交互。
1.1 Tables
family 指下列表类型之一:ip、arp、ip6、bridge、inet、netdev。
# nft list tables [family]
# 显示表中的规则 -n显示地址和其他使用数字格式名称的信息 -a用于显示句柄
# nft [-n] [-a] list table [family] <table_name>
# nft {add | delete | flush} table [family] <table_name>
TABLES
{add | create} table [family] table [ {comment comment ;} { flags 'flags ; }]
{delete | list | flush} table [family] table
list tables [family]
delete table [family] handle handle
1.2 Chains
type 指要创建的 chain 的类型。可能的类型有
- filter:由 arp、bridge、ip、ip6 和 inet 表族支持。
- route:标记数据包(类似于输出钩子的 mangle,其他钩子使用 filter 类型),由 ip 和 ip6 支持。
- nat:执行网络地址转换,由 ip 和 ip6 支持。用于执行网络地址转换(NAT)。
hook (钩子)指的是数据包在内核中处理的特定阶段。更多信息请参阅 Netfilter 钩子。
- ip、ip6 和 inet 系列的钩子包括:prerouting、input、forward、output、postrouting。
- arp 系列的钩子包括:input、output。
- bridge 系列处理穿越网桥设备的以太网数据包。
- netdev 的钩子是:ingress。
priority (优先级)指的是一个数字,用于对链进行排序或在某些 Netfilter 操作之间进行设置。可能的值有 nf_ip_pri_conntrack_defrag(-400)、nf_ip_pri_raw(-300)、nf_ip_pri_selinux_first(-225)、nf_ip_pri_conntrack(-200)、nf_ip_pri_mangle(-150)、 nf_ip_pri_nat_dst(-100)、nf_ip_pri_filter(0)、nf_ip_pri_security(50)、nf_ip_pri_nat_src(100)、nf_ip_pri_selinux_last(225)、nf_ip_pri_conntrack_helper(300)。
policy 是控制基础链中流量的默认判断语句。可能的值有:accept(默认)和 drop。警告: 将策略设置为丢弃会丢弃所有未被规则集接受的数据包。
# nft (add | create) chain [family] <table> <name> [ { type <type> hook <hook> [device <device>] priority <priority> \; [policy <policy> \;] } ]
# nft (delete | list | flush) chain [<family>] <table> <name>
# nft rename chain [<family>] <table> <name> <newname>
CHAINS
{add | create} chain [family] table chain [{ type type hook hook [device device] priority priority ; [policy policy ;] [comment comment ;] }]
{delete | list | flush} chain ['family] table chain
list chains [family]
delete chain [family] table handle handle
rename chain [family] table chain newname
1.3 Rules
handle 是一个内部编号,用于标识某条规则。
position 是一个内部编号,用于在某个句柄之前插入一条规则。
# nft add rule [family] <table> <chain> <matches> <statements>
# nft insert rule [<family>] <table> <chain> [position <position>] <matches> <statements>
# nft replace rule [<family>] <table> <chain> [handle <handle>] <matches> <statements>
# nft delete rule [<family>] <table> <chain> [handle <handle>]
RULES
{add | insert} rule [family] table chain [handle handle | index index] statement ... [comment comment]
replace rule [family] table chain handle handle statement ... [comment comment]
delete rule [family] table chain handle handle
1.3.1 Matches
matches 是用于获取某些数据包信息并据此创建过滤器的线索。
1.3.2 Statements
statements 是当数据包与规则匹配时执行的操作。它可以是终端语句,也可以是非终端语句。在某一规则中,我们可以考虑多个非终端语句,但只能考虑一个终端语句。
Verdict statements 判决语句会改变规则集中的控制流,并对数据包做出策略决定。有效的判决语句有
- accept:接受数据包并停止剩余规则的评估。
- drop:丢弃数据包并停止剩余规则评估。
- queue:将数据包队列到用户空间,并停止剩余规则评估。
- continue:用下一条规则继续评估规则集。
- return:从当前链返回,继续执行上一条链的下一条规则。在基本链中,它等同于接受
- jump
<chain>(跳转<chain>):继续执行<chain>的第一条规则。它将在发出 return 语句后继续执行下一条规则 - goto
<chain>:与跳转类似,但在新链之后,将在最后一条链上继续计算,而不是在包含 goto 语句的那条链上继续计算。
其它statements查看官方wiki表格
1.4 Extras
1.4.1 导出配置
# nft -j list ruleset
该命令已失效 nft export { json | xml } Error: JSON export is no longer supported, use ’nft -j list ruleset’ instead Error: this output type is not supported, use nft -j list ruleset for JSON support instead export xml
1.4.2 监视事件
监控来自 Netlink 的创建过滤器事件。
# nft monitor [new | destroy] [tables | chains | sets | rules | elements] [xml | json]
2. Nft scripting
RULESET
{list | flush} ruleset [family]
2.1 列出规则集
# nft list ruleset
2.2 刷新(清空)规则集
# nft flush ruleset
2.3 加载规则集
创建一个命令批处理文件,并使用 nft 解释器加载它,
# echo "flush ruleset" > /etc/nftables.rules
# echo "add table filter" >> /etc/nftables.rules
# echo "add chain filter input" >> /etc/nftables.rules
# echo "add rule filter input meta iifname lo accept" >> /etc/nftables.rules
# -f 参数表示原子操作
# nft -f /etc/nftables.rules
或创建一个可执行的 nft 脚本文件,
# cat << EOF > /etc/nftables.rules
> #!/usr/local/sbin/nft -f
> flush ruleset
> add table filter
> add chain filter input
> add rule filter input meta iifname lo accept
> EOF
# chmod u+x /etc/nftables.rules
# /etc/nftables.rules
或者从已经创建的规则集创建一个可执行的 nft 脚本文件,
# nft list ruleset > /etc/nftables.rules
# nft flush ruleset
# nft -f /etc/nftables.rules
3. Examples
简单的 ip/ipv6 防火墙
flush ruleset
table firewall {
chain incoming {
type filter hook input priority 0; policy drop;
# established/related connections
ct state established,related accept
# loopback interface
iifname lo accept
# icmp
icmp type echo-request accept
# open tcp ports: sshd (22), httpd (80)
tcp dport {ssh, http} accept
}
}
table ip6 firewall {
chain incoming {
type filter hook input priority 0; policy drop;
# established/related connections
ct state established,related accept
# invalid connections
ct state invalid drop
# loopback interface
iifname lo accept
# icmp
# routers may also want: mld-listener-query, nd-router-solicit
icmpv6 type {echo-request,nd-neighbor-solicit} accept
# open tcp ports: sshd (22), httpd (80)
tcp dport {ssh, http} accept
}
}
Netfilter钩子 和 nftables 与现有 Netfilter 组件的集成
Nerfilter钩子
nftables 主要使用与传统 iptables 相同的 Netfilter 基础设施。挂钩基础架构、连接跟踪系统、NAT 引擎、日志基础架构和用户空间队列都保持不变。只有数据包分类框架是新的。
1. Netfilter 挂钩 Linux 网络数据包流
下图显示了通过 Linux 网络的数据包流向:
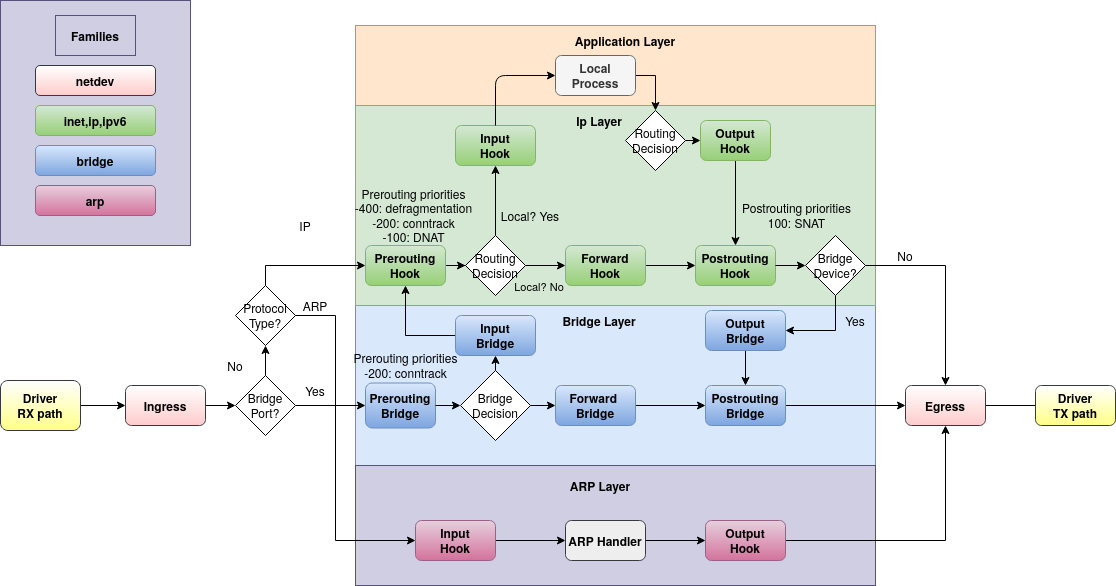
输入路径中流向本地机器的流量会看到预路由和输入钩子。然后,由本地进程产生的流量将遵循输出和后路由路径。
如果将 Linux 操作系统配置为路由器,请不要忘记启用转发功能:
echo 1 > /proc/sys/net/ipv4/ip_forward
这样,不指向本地系统的数据包就会从转发钩子上被看到。此类转发数据包的路径是:prerouting、forward、postrouting。
iptables 在每个钩子(即过滤表中的 INPUT 链)上都预定义了链,而 nftables 则完全没有预定义链。您必须在要过滤流量的每个钩子上明确创建一个基础链。
1.1 入口钩子
入口钩子是在 Linux 内核 4.2 中添加的。与其他 netfilter 钩子不同的是,ingress 钩子与特定的网络接口相连。
你可以使用 nftables 和入口钩子来执行早期过滤策略,这些策略甚至在预路由之前就已生效。请注意,在这个非常早期的阶段,分片数据报尚未重新组装。因此,举例来说,匹配 ip saddr 和 daddr 适用于所有 ip 数据包,但匹配 L4 标头(如 udp dport)只适用于未分片的数据包或第一个分片。
入口钩子提供了 tc 入口过滤的替代方法。你仍然需要使用 tc 进行流量整形/队列管理。
2. 按系列和链类型划分的钩子
下表列出了按系列和链类型划分的可用钩子。最近添加的钩子显示了最低 nftables 和 Linux 内核版本。
3. 钩子内的优先级
在给定钩子内,Netfilter 按数字优先级递增的顺序执行操作。每个 nftables 基本链和流程表都有一个优先级,该优先级定义了它在同一挂钩的其他基本链和流程表以及 Netfilter 内部操作中的排序。例如,预路由钩子上优先级为 -300 的链将被放在连接跟踪操作之前。
下表列出了 Netfilter 优先级值,请查看 nft 手册以获取参考。
从 nftables 0.9.6 开始,您可以使用关键字而不是数字来设置优先级。(请注意,相同的关键字在桥接器系列与其他系列中对应不同的数字优先级)。您也可以将优先级指定为关键字的积分偏移,例如,mangle - 5 相当于数字优先级 -155。
即使在逻辑上不合理的系列/挂钩组合中,也可以指定关键字优先级。请记住,对于 Netfilter 而言,给定钩子中优先级的相对数字排序才是最重要的。请记住,这种相对排序包括数据包碎片整理、连接跟踪和其他 Netfilter 操作以及 nftables 基本链和 flowtables。
注意:nat 类型链必须使用优先级 > -200,这是 Conntrack 挂钩使用的优先级。
Nftables families
Netfilter 支持多级网络过滤。使用 iptables 时,每个级别都有一个单独的工具:iptables、ip6tables、arptables、ebtables。有了 nftables,多个网络级别被抽象为 families,所有系列都由单一工具 nft 提供服务。
请注意,您能看到哪些流量/数据包,以及在网络堆栈中的哪个点看到这些流量/数据包,取决于您使用的挂钩。
以下是当前 nftables 系列的说明。将来可能会添加其他系列。
1. ip
该系列的表可以查看 IPv4 流量/数据包。iptables 工具相当于传统的 x_tables。
2. ip6
该系列的表可以查看 IPv6 流量/数据包。ip6tables 工具相当于传统的 x_tables。
3. inet
该系列的表可同时查看 IPv4 和 IPv6 流量/数据包,从而简化了双协议栈支持。
在 inet 系列的表内,IPv4 和 IPv6 数据包都会穿越相同的规则。针对 IPv4 数据包的规则不会影响 IPv6 数据包,反之亦然。针对第 3 层协议的规则对两者都有影响。无论数据包是 IPv4 还是 IPv6,都可以使用 meta l4proto 来匹配第 4 层协议。
Examples:
# This rule affects only IPv4 packets:
add rule inet filter input ip saddr 1.1.1.1 counter accept
# This rule affects only IPv6 packets:
add rule inet filter input ip6 daddr fe00::2 counter accept
# These rules affect both IPv4 and IPv6 packets:
add rule inet filter input ct state established,related counter accept
add rule inet filter input udp dport 53 accept
nftables 0.9.7 和 Linux 内核 4.10 中新增了 inet 系列入口钩子,它的过滤位置与 netdev 入口钩子相同。
4. arp
在内核进行任何 L3 处理之前,该系列的表会查看 ARP 级(即 L2)流量。arptables 工具相当于传统的 x_tables。
5. bridge
该系列的表格可查看穿越网桥(即交换)的流量/数据包。对 L3 协议不做任何假设。
ebtables 工具相当于传统的 x_tables。一些旧的 x_tables 模块(如 physdev)最终也将由 nftables 桥接器系列提供服务。
请注意,nftables 桥接器系列没有集成 nf_conntrack。
6. netdev
netdev 系列与其他系列不同,它用于创建连接到单个网络接口的基础链。此类基础链可查看指定接口上的所有网络流量,而无需假设 L2 或 L3 协议。因此,您可以从这里过滤 ARP 流量。没有与 netdev 系列相当的传统 x_tables。
该系列的主要(唯一?)用途是使用 Linux 内核 4.2 中新增的入口钩子(ingress hook)的基础链。这种入口链会在网卡驱动程序将网络数据包传递到网络堆栈后看到这些数据包。这种在数据包路径中的早期位置非常适合丢弃与 DDoS 攻击相关的数据包。从入口链丢弃数据包的效率是从预路由链丢弃数据包效率的两倍。(请注意,在入口链中,分片数据报尚未重新组装。因此,举例来说,匹配 ip saddr 和 daddr 适用于所有 ip 数据包,但匹配 L4 标头(如 udp dport)只适用于未分片的数据包或第一个分片)。
入口钩子提供了 tc 入口过滤的替代方法。你仍然需要使用 tc 进行流量整形/队列管理。
你还可以使用入口钩子进行负载平衡,包括直接服务器返回(DSR),据说速度快 10 倍。
数据类型
1. nft describe
您可以使用 nft describe 获取有关数据类型的信息,找出特定选择符的数据类型,并列出该选择符的预定义符号常量。例如:
# nft describe iif
meta expression, datatype iface_index (network interface index) (basetype integer), 32 bits
# nft describe iifname
meta expression, datatype ifname (network interface name) (basetype string), 16 characters
# nft describe tcp flags
payload expression, datatype tcp_flag (TCP flag) (basetype bitmask, integer), 8 bits
pre-defined symbolic constants (in hexadecimal):
fin 0x01
syn 0x02
rst 0x04
psh 0x08
ack 0x10
urg 0x20
ecn 0x40
cwr 0x80
2. 数据类型列表
连接跟踪系统
nftables 使用 netfilter 的连接跟踪系统(通常称为 conntrack 或 ct)将网络数据包与连接以及这些连接的状态联系起来。nftables 规则集根据数据包是否是所跟踪连接的有效部分来应用策略,从而执行有状态防火墙。
nftables 还经常使用 Netfilter 的 NAT 引擎执行网络地址转换,该引擎本身就是建立在 conntrack 的基础上。你可以使用 nft 配置 NAT。
从技术上讲,conntrack 和 nftables(以及 NAT)是 netfilter 的不同组件。尽管如此,conntrack 还是经常与 nftables 一起使用,因此值得在此提供相关概述和更多文档参考。
基本操作
配置表
表是 nftables 规则集中的顶级容器;它们包含链、集、映射、流表和有状态对象。
每个表正好属于一个族。因此,您的规则集需要为每个要过滤的族至少配备一个表。
以下是配置表的一些基本操作和命令:
1. 添加表
nft add table ip filter
2. 显示表
nft list tables
3. 删除表
nft delete table ip foo
故障排除: 自 Linux 内核 3.18 起,你可以用这条命令删除表及其内容。早期的内核要求先刷新表的内容,否则会出错:
% nft delete table filter <cmdline>:1:1-19: Error: Could not delete table: Device or resource busy delete table filter ^^^^^^^^^^^^^^^^^^^
4. 清空表
您可以使用以下命令删除属于此表的所有规则:
% nft flush table ip filter
这将删除在该表中注册的每个链的规则。
注意:nft flush table ip filter 不会刷新在该表中定义的集,如果要刷新的表不存在且使用的是 <4.9.0 版 Linux,则会导致出错,这可以通过刷新规则集来解决。
配置链
与 iptables 一样,nftables 也是将规则附加到链上。与 iptables 不同,nftables 没有 INPUT、OUTPUT 等预定义链。相反,要在特定处理步骤中过滤数据包,你需要明确创建一个基本链,名称由你选择,并将其附加到相应的 Netfilter 钩子上。这样,Netfilter 就能进行非常灵活的配置,而不会因为规则集不需要的内置链而减慢速度。
1. 添加基础链
基础链是注册到 Netfilter 钩子中的链,即这些链可以看到流经 Linux TCP/IP 堆栈的数据包。
添加基础链的语法是:
% nft add chain [family] <table_name> <chain_name> { type <type> hook <hook> priority <value> \; [policy <policy> \;] [comment \"text comment\" \;] }
下面的示例展示了如何向 foo 表(必须是之前创建的)添加新的基础链输入:
% nft 'add chain ip foo input { type filter hook input priority 0 ; }'
重要:nft 会重复使用特殊字符,例如大括号和分号。如果使用 bash 等 shell 运行这些命令,则需要转义所有特殊字符。防止 shell 尝试解析 nft 语法的最简单方法是将所有字符都用单引号引出。或者,也可以运行命令
nft -i
并在交互模式下运行 nft。
add chain 命令用于注册连接到输入钩子的输入链,这样它就能看到向本地进程发送的数据包。
优先级很重要,因为它决定了链的排序,因此,如果输入钩子中有多个链,就可以决定哪个链先看到数据包。例如,优先级为 -12、-1、0、10 的输入链将按此顺序被访问。可以给两个基础链相同的优先级,但不能保证附加到同一钩子位置的具有相同优先级的基础链的评估顺序。
如果要使用 nftables 过滤桌面 Linux 计算机(即不转发流量的计算机)的流量,也可以注册输出链:
% nft 'add chain ip foo output { type filter hook output priority 0 ; }'
现在你可以过滤传入(指向本地进程)和传出(由本地进程产生)的流量了。
重要提示:如果不包含大括号中指定的链配置,则创建的普通链将看不到任何数据包(类似于 iptables -N chain-name)。
自 nftables 0.5 起,您也可以像在 iptables 中一样为基础链指定默认策略:
% nft 'add chain ip foo output { type filter hook output priority 0 ; policy accept; }'
与 iptables 一样,两种可能的默认策略是接受和丢弃。
在入口钩子上添加链时,必须指定链将连接的设备:
% nft 'add chain netdev foo dev0filter { type filter hook ingress device eth0 priority 0 ; }'
1.1 基础链类型
可能的链类型有:
- filter(过滤),用于过滤数据包。arp、bridge、ip、ip6 和 inet 表系列都支持这种类型。
- route(路由),用于在任何相关 IP 头字段或数据包标记被修改时重新路由数据包。如果你熟悉 iptables,该链类型提供了与 mangle 表相同的语义,但仅适用于输出钩子(对于其他钩子,请使用 filter 类型)。ip、ip6 和 inet 表族都支持该类型。
- nat 用于执行网络地址转换(NAT)。只有给定数据流的第一个数据包才会进入此链;随后的数据包会绕过此链。因此,切勿使用此链进行过滤。ip、ip6 和 inet 表系列都支持 nat 链类型。
1.2 基础链钩子
在配置基础链时可以使用的钩子有
- ingress(自 Linux 内核 4.2 起仅在 netdev 系列中使用,自 Linux 内核 5.10 起在 inet 系列中使用):在数据包从网卡驱动传上来之后,甚至在预路由之前,就能立即看到它们。这样,你就有了除 tc 之外的另一种选择。
- prerouting:在作出任何路由决定之前,就能看到所有传入的数据包。数据包的地址可能是本地系统,也可能是远程系统。
- input:查看寻址到本地系统并已路由到本地系统及其运行进程的传入数据包。
- forward:查看未寻址到本地系统的传入数据包。
- output:查看来自本地计算机进程的数据包。
- postrouting(路由后):查看路由后的所有数据包,即在它们离开本地系统之前。
1.3 基础链优先级
每个 nftables 基本链都被分配了一个优先级,该优先级定义了它在同一挂钩的其他基本链、流表和 Netfilter 内部操作中的排序。例如,预路由钩子上优先级为 -300 的链将被放在连接跟踪操作之前。
注意:如果数据包已被接受,但存在另一个具有相同钩子类型且优先级较高的链,那么数据包随后将穿越另一个链。因此,无论是通过规则还是默认链策略做出的接受决定都不一定是最终的。然而,数据包被丢弃的情况却并非如此。相反,丢弃会立即生效,不会再评估其他规则或链。
下面的规则集展示了这种可能令人吃惊的行为区别:
table inet filter {
# This chain is evaluated first due to priority
chain services {
type filter hook input priority 0; policy accept;
# If matched, this rule will prevent any further evaluation
tcp dport http drop
# If matched, and despite the accept verdict, the packet proceeds to enter the chain below
tcp dport ssh accept
# Likewise for any packets that get this far and hit the default policy
}
# This chain is evaluated last due to priority
chain input {
type filter hook input priority 1; policy drop;
# All ingress packets end up being dropped here!
}
}
如果将上述 “输入 “链的优先级改为-1,唯一的区别就是没有数据包有机会进入 “服务 “链。无论如何,这个规则集都会导致所有入口数据包被丢弃。
总之,数据包将遍历给定钩子范围内的所有链,直到被丢弃或不再存在基本链为止。只有在没有与数据包最初进入的链具有相同钩子类型的链时,才会保证接受判决是最终判决。
Netfilter 的钩子执行机制在 Pablo 有关连接跟踪的论文中有更详细的描述。
1.4 基础链策略
这是将应用于到达链末端(即没有更多规则需要评估)的数据包的默认判定。
目前有两种策略:accept(默认)或 drop。
- 接受判定意味着数据包将继续穿越网络堆栈(默认)。
- 丢弃判决意味着,如果数据包到达基础链的末端,就会被丢弃。
注意:如果没有明确选择策略,将使用默认策略接受。
2. 添加常规链
您还可以创建常规链,类似于 iptables 用户定义链:
# nft -i
nft> add chain [family] <table_name> <chain_name> [{ [policy <policy> ;] [comment "text comment about this chain" ;] }]
链名是任意字符串,大小写不限。
请注意,添加常规链时不包含钩子关键字。由于没有连接到 Netfilter 钩子,常规链本身不会看到任何流量。但一个或多个基础链可以包含跳转或转到此链的规则–在跳转或转到此链后,正则链会以与调用基础链完全相同的方式处理数据包。通过使用跳转和/或 goto 操作,将规则集排列成基础链和常规链的树状结构,这非常有用。(虽然我们说得有点超前,但 nftables vmaps 提供了一种更强大的方法来构建高效的分支规则集)。
3. 删除链
您可以将链删除为:
% nft delete chain [family] <table_name> <chain_name>
唯一的条件是要删除的链必须为空,否则内核会抱怨该链仍在使用中。
% nft delete chain ip foo input
<cmdline>:1:1-28: Error: Could not delete chain: Device or resource busy
delete chain ip foo input
^^^^^^^^^^^^^^^^^^^^^^^^^
在移除链之前,您必须清除该链中的规则集。
4. 冲洗链
清除(删除)foo 表链输入中的所有规则:
# nft flush chain foo input
5. 配置示例: 过滤独立计算机的流量
您可以创建一个包含两个基本链的表,以定义规则来过滤进出您计算机的流量,前提是 IPv4 连接:
# nft add table ip filter
# nft 'add chain ip filter input { type filter hook input priority 0 ; }'
# nft 'add chain ip filter output { type filter hook output priority 0 ; }'
现在,你可以开始为这两个基础链附加规则了。请注意,本例中不需要转发链,因为本例假定 nftables 是用来过滤不作为路由器的独立电脑的流量。
简单规则管理
规则根据网络数据包是否符合指定标准对其采取行动(如接受或丢弃)。
每个规则由零个或多个表达式组成,后面跟一个或多个语句。每个表达式测试数据包是否与特定的有效载荷字段或数据包/流元数据相匹配。多个表达式从左到右进行线性评估:如果第一个表达式匹配,则评估下一个表达式,依此类推。如果到达最后一个表达式,那么数据包就匹配了规则中的所有表达式,规则的语句就会被执行。每条语句都会执行一项操作,如设置 netfilter 标记、计算数据包、记录数据包或做出判断,如接受或丢弃数据包或跳转到另一条链。与表达式一样,多个语句从左到右进行线性评估:通过使用多个语句,一条规则可以执行多个操作。请注意,判决语句的本质是结束规则。
以下是配置规则的一些基本操作和命令:
1. 添加新规则
要添加新规则,必须指定相应的表格和要使用的链,例如
# nft add rule filter output ip daddr 8.8.8.8 counter
其中 filter 是表,output 是链。上面的示例添加了一条规则,用于匹配输出链中所有目的地为 8.8.8.8 的数据包,如果匹配成功,则更新规则计数器。注意,计数器在 nftables 中是可选的。
对于熟悉 iptables 的人来说,规则添加等同于 iptables 中的 -A 命令。
2. 列出规则
您可以使用以下命令列出表格中包含的规则:
# nft list table filter
table ip filter {
chain input {
type filter hook input priority 0;
}
chain output {
type filter hook output priority 0;
ip daddr 8.8.8.8 counter packets 0 bytes 0
tcp dport ssh counter packets 0 bytes 0
}
}
例如,您还可以按链条列出规则:
# nft list chain filter ouput
table ip filter {
chain output {
type filter hook output priority 0;
ip daddr 8.8.8.8 counter packets 0 bytes 0
tcp dport ssh counter packets 0 bytes 0
}
}
在列出规则时,可以使用大量输出文本修饰符,例如将 IP 地址转换为 DNS 名称、TCP 协议等。
3. 测试规则
让我们用一个简单的 ping 到 8.8.8.8 来测试这条规则:
# ping -c 1 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_req=1 ttl=64 time=1.31 ms
然后,如果我们列出规则集,就会得到
# nft -nn list table filter
table ip filter {
chain input {
type filter hook input priority 0;
}
chain output {
type filter hook output priority 0;
ip daddr 8.8.8.8 counter packets 1 bytes 84
tcp dport 22 counter packets 0 bytes 0
}
}
请注意,计数器已更新。
4. 在指定位置添加规则
如果要在给定位置添加一条规则,必须使用句柄作为参考:
# nft -n -a list table filter
table filter {
chain output {
type filter hook output priority 0;
ip protocol tcp counter packets 82 bytes 9680 # handle 8
ip saddr 127.0.0.1 ip daddr 127.0.0.6 drop # handle 7
}
}
如果要在处理程序编号为 8 的规则后添加一条规则,则必须键入
# nft add rule filter output position 8 ip daddr 127.0.0.8 drop
现在,您可以通过列出规则集来检查该命令的效果:
# nft -n -a list table filter
table filter {
chain output {
type filter hook output priority 0;
ip protocol tcp counter packets 190 bytes 21908 # handle 8
ip daddr 127.0.0.8 drop # handle 10
ip saddr 127.0.0.1 ip daddr 127.0.0.6 drop # handle 7
}
}
如果要在处理程序编号为 8 的规则之前插入一条规则,则必须键入
# nft insert rule filter output position 8 ip daddr 127.0.0.8 drop
5. 删除规则
要删除一条规则,必须通过 -a 选项获取句柄。内核会自动分配句柄,它是规则的唯一标识。
# nft -a list table filter
table ip filter {
chain input {
type filter hook input priority 0;
}
chain output {
type filter hook output priority 0;
ip daddr 192.168.1.1 counter packets 1 bytes 84 # handle 5
}
}
您可以使用以下命令删除句柄为 5 的规则:
# nft delete rule filter output handle 5
注:计划支持通过传递删除规则:
# nft delete rule filter output ip saddr 192.168.1.1 counter
但这一功能尚未实现。因此,在该功能实现之前,您必须使用句柄来删除规则。
6. 删除链中的所有规则
您可以使用以下命令删除链中的所有规则:
# nft flush chain filter output
您还可以使用以下命令删除表中的所有规则:
# nft flush table filter
7. 添加新规则
通过插入命令预置新规则:
# nft insert rule filter output ip daddr 192.168.1.1 counter
这条规则将更新指向 192.168.1.1 的流量的数据包和字节计数器。
iptables 中的对应规则是
# iptables -I OUTPUT -t filter -d 192.168.1.1
请注意,iptables 总是按规则提供计数器。
8. 替换规则
你可以通过 replace 命令替换任何规则,只需指出规则句柄即可,你必须先用选项 -a 列出规则集,才能找到规则句柄:
# nft -a list ruleset
table ip filter {
chain input {
type filter hook input priority 0; policy accept;
ip protocol tcp counter packets 0 bytes 0 # handle 2
}
}
要替换句柄 2 的规则,请指定其句柄编号和要替换的新规则:
# nft replace rule filter input handle 2 counter
列出上述替换后的规则集:
# nft list ruleset
table ip filter {
chain input {
type filter hook input priority 0; policy accept;
counter packets 0 bytes 0
}
}
可以看到,计算 TCP 数据包的旧规则已被计算所有数据包的新规则取代。
原子规则替换
1. 关于 Shell 脚本 + nftables 的警告
在使用 iptables 时,通常使用由多个 iptables 命令组成的 bash 脚本来配置防火墙。这种方法并不理想,因为它不是原子式的,也就是说,在 bash 脚本运行的几分之一秒内,防火墙处于部分配置状态。Nftables 使用 -f 选项引入了原子规则替换。这与 bash 脚本不同,因为 Nftables 会读取所有包含的配置文件,在内存中创建配置对象,与现有配置并存,然后在一次原子操作中将旧配置替换为新配置,这意味着防火墙不会处于部分配置状态。
2. 原子规则替换
您可以使用 -f 选项原子式更新规则集:
# nft -f file
其中的文件包含您的规则集。
您可以通过在文件中存储现有列表来保存您的规则集,即:”……"。
# nft list table filter > filter-table
然后就可以使用 -f 选项进行还原:
# nft -f filter-table
2.1 注意事项
请注意这些注意事项:
- 创建表格:在加载使用 nft list table filter > filter-table 导出的文件之前,您可能必须使用 nft create table ip filter 创建表格,否则会因为表格不存在而出错。较新的 nftables 版本在这方面的表现更加一致。
- 重复规则: 如果在 filter-table 文件开头加上 flush table filter 行,就能实现与 iptables-restore 相同的原子规则集替换。内核会在一次事务中处理文件中的规则命令,所以基本上刷新和加载新规则都是一次性完成的。如果选择不刷新表,那么每次重新加载配置时都会看到重复的规则。
- 刷新集:刷新表过滤器不会刷新该表中定义的任何集。要同时刷新集,请使用 flush ruleset(自 Linux 3.17 起可用)或明确删除集。早期版本(Linux <=3.16)不允许导入已存在的数据集,但以后的版本允许这样做。
- 如果包含两个文件,而每个文件都有一个过滤表语句,会发生什么情况?如果有两个包含过滤表语句的文件,但其中一个添加了允许来自 192.168.1.1 的流量的规则,另一个添加了允许来自 192.168.1.2 的流量的规则,那么这两个规则都将包含在链中,即使其中一个或两个文件都包含了清除语句。
- 其中一个文件或两个文件中都没有 flush 语句怎么办?如果任何包含的文件中有 flush 命令,那么这些命令将在执行配置交换时运行,而不是在加载文件时运行。如果在任何包含的文件中不包含 flush 语句,就会出现重复的规则。如果包含 flush 语句,则不会出现重复规则,两个文件中的配置都会包含在内。
命令行的错误报告
当您使用了错误的数据类型时,nft 命令行实用程序会尝试帮助您。
以下示例显示了将 IPv4 地址作为 TCP 端口时的错误输出。
# nft add rule filter input tcp dport 1.1.1.1 counter drop
<cmdline>:1:33-39: Error: Could not resolve service: Servname not supported for ai_socktype
add rule filter input tcp dport 1.1.1.1 counter drop
^^^^^^^
如果命令不完整,典型的输出结果如下:
# nft add rule filter input tcp dport
<cmdline>:1:32-32: Error: syntax error, unexpected end of file
add rule filter input tcp dport
^
通过表达式构建规则
nftables 提供以下内置操作:
- eq 表示相等。也可以使用 ==
- ne 表示不等于。或者使用 !=
- lt 表示小于。或者使用 <
- gt 表示大于。或者使用 >
- le 表示小于或等于。或者使用 <=
- ge 表示大于或等于。或者使用 >=
注意:如果在 shell 中使用 < 和 > 符号,shell 会将其分别解释为标准输入和输出重定向。你需要将它们转义,例如:<
下面的示例展示了如何匹配所有不是来自 TCP/22 端口的传入流量。
# nft add rule filter input tcp dport != 22
同样,您也可以使用以下命令匹配来自高端口的流量:
# nft add rule filter input tcp dport >= 1024
规则集级别的操作
1. 使用本地 nft 语法
Linux 内核 3.18 在管理整个规则集的可用操作方面做了一些改进。
1.1 列出
列出完整的规则集:
# nft list ruleset
列出每个族的规则集:
# nft list ruleset arp
# nft list ruleset ip
# nft list ruleset ip6
# nft list ruleset bridge
# nft list ruleset inet
这些命令将打印指定族的所有表/链/集/规则。
1.2 清除
此外,您还可以刷新(擦除、删除、清除)整个规则集:
# nft flush ruleset
也可以按 family 操作:
# nft flush ruleset arp
# nft flush ruleset ip
# nft flush ruleset ip6
# nft flush ruleset bridge
# nft flush ruleset inet
1.3 备份/恢复
您可以结合上述两条命令来备份您的规则集:
# echo "flush ruleset" > backup.nft
# nft list ruleset >> backup.nft
并以原子方式加载:
# nft -f backup.nft
2. 以 JSON 格式列出
您也可以以 JSON 格式导出规则集,只需通过”–json “选项即可:
# nft --json list ruleset > ruleset.json
监视规则集更新
nft 可以通过以下方式显示规则集更新通知:
# nft monitor
这将使 nft 订阅任何类型的规则集更新。
您可以过滤掉每种类型的事件:
- 对象:表、链、规则、集和元素。
事件:新建和销毁。 输出格式可以是
- 纯文本(即本地 nft 格式)
- xml
- json
下面的示例展示了如何仅跟踪规则更新:
# nft monitor rules
如果您只想接收新规则:
# nft monitor new rules
更完善一点的例子
在终端中键入以下内容
term1% nft monitor
在不同的终端上,如果键入以下内容
term2% nft add table inet filter
term2% nft add chain inet filter forward
term2% nft add rule inet filter forward counter accept
term2% nft flush chain inet filter forward
term2% nft flush ruleset
然后,如果你回到term 1,你就会看到:
term1% nft monitor
add table inet filter
add chain inet filter forward
add rule inet filter forward counter packets 0 bytes 0 accept
delete rule inet filter forward handle 4
delete chain inet filter forward
delete table inet filter
脚本
许多人喜欢在 shell 脚本中维护规则集,这样可以添加注释,并以更人性化的方式排列规则。但这样做也有问题,因为在应用规则集时,shell 脚本会破坏原子性,因此在加载规则集时,过滤策略会以不一致的方式应用。
幸运的是,nftables 提供了一个本地脚本环境来解决这些问题,它基本上允许你包含其他规则集文件、定义变量和添加注释。您必须通过 nft -f my-ruleset.file 命令来恢复本机脚本的内容。
要创建 nftables 脚本,必须在脚本文件中添加以下标题:
#!/usr/sbin/nft -f
1. 添加注释
您可以使用 “#“字符在文件中添加注释。#“之后的内容将被忽略。
#!/usr/sbin/nft -f
#
# table declaration
#
add table filter
#
# chain declaration
#
add chain filter input { type filter hook input priority 0; policy drop; }
#
# rule declaration
#
add rule filter input ct state established,related counter accept
2. 包括文件
使用 include 语句可以包含其他文件。可以使用 -I/–includepath 选项指定要搜索 include 文件的目录。你可以在路径前加上”./",强制包含位于当前工作目录下的文件(即相对路径),也可以用”/“表示绝对路径下的文件。
如果未指定 -I/–includepath,nft 将依赖编译时指定的默认目录。你可以通过-h/–help选项获取默认目录。
包含语句支持常用的 shell 通配符(*, ?,[] )。如果在 include 语句中使用了通配符,则没有匹配的 include 语句也不是错误。
这就允许在 include “/etc/firewall/rules/” 这样的语句中使用可能为空的 include 目录。通配符按字母顺序加载。
注意:include 语句不匹配以点(.)开头的文件。
#!/usr/sbin/nft -f
# include a single file using the default search path
include "ipv4-nat.ruleset"
# include all files ending in *.nft in the default search path
include "*.nft"
# include all files in a given directory using an absolute path
include "/etc/nftables/*"
3. 定义变量
您可以使用定义关键字来定义变量,下面的示例显示了一个非常简单的规则集,用于记录来自 8.8.8.8(常用的 Google DNS 服务器)的流量:
#!/usr/sbin/nft -f
define google_dns = 8.8.8.8
add table filter
add chain filter input { type filter hook input priority 0; }
add rule filter input ip saddr $google_dns counter
您还可以为集合定义一个变量:
#!/usr/sbin/nft -f
define ntp_servers = { 84.77.40.132, 176.31.53.99, 81.19.96.148, 138.100.62.8 }
add table filter
add chain filter input { type filter hook input priority 0; }
add rule filter input ip saddr $ntp_servers counter
不要忘记,在规则中使用括号时,括号具有特殊的语义,因为括号表示该变量代表一个集合。因此,请避免使用以下语句
define google_dns = { 8.8.8.8 }
定义一个只存储一个元素的集合简直是矫枉过正,不如使用单例定义:
define google_dns = 8.8.8.8
4. 文件格式
nft -f <filename> 接受两种格式,第一种是在 nft 列表表输出中看到的格式。第二种是使用相同的语法多次调用 nft 二进制文件,但以原子方式调用。
nftables 输出格式示例:
#!/usr/sbin/nft -f
define ntp_servers = { 84.77.40.132, 176.31.53.99, 81.19.96.148, 138.100.62.8 }
#flush table nat
table ip nat {
chain prerouting {
type filter hook prerouting priority 0; policy accept;
ip saddr $ntp_servers counter
}
chain postrouting {
type filter hook postrouting priority 100; policy accept;
}
}
脚本配置格式示例
#!/usr/sbin/nft -f
define ntp_servers = { 84.77.40.132, 176.31.53.99, 81.19.96.148, 138.100.62.8 }
add table filter
add chain filter input { type filter hook input priority 0; }
add rule filter input ip saddr $ntp_servers counter
您可以自由转换这两种格式,因为它们的语法基本相同(只是组织结构不同)。根据您的使用情况,您可能希望在构建防火墙时使用其中一种格式。
5. 从脚本构建 nft 文件
虽然不一定推荐使用这种方法,但您可以使用自己选择的脚本语言,以 nft 可接受的格式(见上节)创建一个文本文件,然后使用 nft -f <your_file_in_nft_format> 原子加载防火墙配置。如果要将 nft 配置与使用不同文件格式和命令行工具的其他子系统的配置进行协调,则可能需要使用这种方法。
6. 在 Python 中使用 nftables
通过高级库 libnftables,可以在 Python 程序中使用 nft 命令行实用程序提供的相同功能。更多信息和示例请参阅下文:
- 如何在 Python 中使用 nftables,Arturo Borrero,2020-11-22;
- 与上述内容配套的 python nftables 教程代码示例。
规则集调试/跟踪
自 nftables v0.6 和 linux kernel 4.6 起,支持规则集调试/跟踪。
这等同于旧版 iptables 的 -J TRACE 方法,但有一些重大改进。
启用调试/跟踪的步骤如下:
- 在规则集中提供支持(在任意规则中设置 nftrace)
- 监控来自 nft 工具的跟踪事件
1. 启用 nftrace
要在数据包中启用 nftrace,请使用包含此语句的规则:
# meta nftrace set 1
毕竟,nftrace 是数据包元信息的一部分。
当然,您可以只对特定匹配数据包启用 nftrace。在下面的示例中,我们只对 tcp 数据包启用 nftrace:
# ip protocol tcp meta nftrace set 1
要正确调试规则集,关键是要调整 nftrace,使其仅适用于所需数据包的子集,否则可能会获得大量调试/跟踪信息,让人应接不暇。
2. 使用链启用跟踪
建议启用跟踪的方法是为此添加一个链。
注册跟踪链以启用跟踪功能。如果已有预路由链,请确保跟踪链的优先级在现有预路由链之前。
# nft add chain filter trace_chain { type filter hook prerouting priority -301\; }
# nft add rule filter trace_chain meta nftrace set 1
本例假定您已有一个原始预路由链(优先级为 -300),因此会在此链(优先级为 -301)之前注册一个跟踪链。
一旦完成规则跟踪,就可以直接删除此链来禁用它:
# nft delete chain filter trace_chain
3. 监控跟踪事件
在 nftables 中,获取调试/跟踪事件与 iptables 世界有些不同。现在,我们有一个基于事件的内核监控器来通知 nft 工具。
基本语法如下
# nft monitor trace
每个跟踪事件都会分配一个 “id”,方便您跟踪同一跟踪会话中的不同数据包。
4. 完整示例
下面是该调试/跟踪机制工作的完整示例。
假设您拥有此规则集:
table ip filter {
chain input {
type filter hook input priority filter; policy drop;
ct state established,related counter packets 2 bytes 292 accept
ct state new tcp dport 22 counter packets 0 bytes 0 accept
}
}
加载此规则集:
# nft -f ruleset.nft
然后,添加一条可以进行跟踪的链:
# nft add chain ip filter trace_chain { type filter hook prerouting priority -1\; }
这将在现有输入链之前注册 trace_chain。
以及启用跟踪的规则:
# nft add rule ip filter trace_chain meta nftrace set 1
通过 ping 一台主机进行简单的跟踪测试:
# ping -c 1 8.8.8.8
你在不同的终端上运行:
# nft monitor trace
trace id a95ea7ef ip filter trace_chain packet: iif "enp0s25" ether saddr 00:0d:b9:4a:49:3d ether daddr 3c:97:0e:39:aa:20 ip saddr 8.8.8.8 ip daddr 192.168.2.118 ip dscp cs0 ip ecn not-ect ip ttl 115 ip id 0 ip length 84 icmp type echo-reply icmp code net-unreachable icmp id 9253 icmp sequence 1 @th,64,96 24106705117628271805883024640
trace id a95ea7ef ip filter trace_chain rule meta nftrace set 1 (verdict continue)
trace id a95ea7ef ip filter trace_chain verdict continue
trace id a95ea7ef ip filter trace_chain policy accept
trace id a95ea7ef ip filter input packet: iif "enp0s25" ether saddr 00:0d:b9:4a:49:3d ether daddr 3c:97:0e:39:aa:20 ip saddr 8.8.8.8 ip daddr 192.168.2.118 ip dscp cs0 ip ecn not-ect ip ttl 115 ip id 0 ip length 84 icmp type echo-reply icmp code net-unreachable icmp id 9253 icmp sequence 1 @th,64,96 24106705117628271805883024640
trace id a95ea7ef ip filter input rule ct state established,related counter packets 168 bytes 53513 accept (verdict accept)
跟踪 id 可唯一标识数据包。跟踪描述了最初进入链的数据包。
trace id a95ea7ef ip filter trace_chain packet: iif "enp0s25" ether saddr 00:0d:b9:4a:49:3d ether daddr 3c:97:0e:39:aa:20 ip saddr 8.8.8.8 ip daddr 192.168.2.118 ip dscp cs0 ip ecn not-ect ip ttl 115 ip id 0 ip length 84 icmp type echo-reply icmp code net-unreachable icmp id 9253 icmp sequence 1 @th,64,96 24106705117628271805883024640
然后,数据包通过规则集传输。
规则集调试/VM 代码分析
在内核中,nf_tables 是作为虚拟机实现的,有自己的指令集。内核的表达式实现了这些指令。在用户空间中,映射(不一定)像这样直接。
1. 用户空间中的语句和表达式
在用户空间术语中,语句和表达式是有区别的;相关区别在于前者本身是规则的有效组成部分,而后者通常作为语句的参数或输入出现。例如,下面是有效负载语句:
ip dscp set 42
在这里,ip dscp 是一个表达式,用于确定要篡改数据包有效载荷的哪一部分,42 是一个常量表达式,表示要分配的值。在 set 关键字后出现的内容有一定的限制,nft 会进行一些类型检查,以确保它们是兼容的。下面举例说明这一概念的强大功能:
tcp dport set tcp sport
这将改变 TCP 数据包的目标端口,使其与源端口值相匹配。尽管有点结构化,但这是一个语句接受来自两个表达式的数据的例子。
2. 内核空间中的表达式
内核没有语句的概念。只有表达式(指令)从寄存器加载数据或向寄存器写入数据,从而相互影响。除了 20 个通用数据寄存器(每个寄存器大小为 4 字节)外,还有一个用于终止规则的判决寄存器,甚至是表达式可用的链式遍历。
3. 虚拟机字节码的运行
当 nft 将用户输入转化为内核的虚拟机代码时,它会将用户空间的语句和表达式转化为调用内核表达式的虚拟机代码。通过 –debug=netlink 选项可以使这一过程可视化:
# nft --debug=netlink add rule inet t c ip daddr 10.1.2.3 counter accept
inet t c
[ meta load nfproto => reg 1 ]
[ cmp eq reg 1 0x00000002 ]
[ payload load 4b @ network header + 16 => reg 1 ]
[ cmp eq reg 1 0x0302010a ]
[ counter pkts 0 bytes 0 ]
[ immediate reg 0 accept ]
上述命令添加的规则会将数据包的 IPv4 目的地址字段与值 10.1.2.3 进行匹配,对匹配的数据包进行计数并最终接受它们(从而结束对该数据包的链式遍历)。
打印出的虚拟机字节码揭示了一些更有趣的细节:
- 该规则实际上是从匹配 meta nfproto 值开始的: 由于链位于 inet 系列中,因此它也可能看到 IPv4 以外的数据包。这种过滤是必要的,因为
- 用户空间的 ip daddr 表达式实际上非常通用: 它转换成的有效载荷表达式只是将网络报头偏移 16B 处的 4B 加载到寄存器 1 中。对于 IPv6 数据包,这将很容易加载源地址字段的部分内容,甚至可能意外匹配到 0x0302010a 的值。为避免这种意外(和不可预见)行为,需要使用隐式元 nfproto 匹配。
- 数据包匹配通常是隐式的: 第二个表达式将元 nfproto 值与 0x02(= NFPROTO_IPV4)进行比较,以确定是否相等 (eq)。如果不成功,它将把值 NFT_BREAK 写入判定寄存器,然后用下一条规则继续链式遍历。
- 与上述情况相反,最后一个表达式是对判定寄存器(寄存器 0)的显式访问,写入 NF_ACCEPT。
4. 虚拟机字节码中的语句
从上面的例子中选取一个:
nft --debug=netlink add rule t c tcp dport set tcp sport
ip t c
[ meta load l4proto => reg 1 ]
[ cmp eq reg 1 0x00000006 ]
[ payload load 2b @ transport header + 0 => reg 1 ]
[ payload write reg 1 => 2b @ transport header + 2 csum_type 1 csum_off 16 csum_flags 0x0 ]
这揭示了有效载荷语句实际上只是内核 “有效载荷表达式 “的一个变体,它是写入而不是读取。还有一些观察结果:
- 再次出现隐式匹配,这次是断言元 l4proto 匹配值 0x6(= IPPROTO_TCP)。再次确保下面的有效载荷表达式不会读取垃圾信息或写入数据包的奇怪部分。
- 第二个 “有效载荷表达式 “还保存了部分校验和更新的额外信息,这在篡改 IPv4 数据包后是必要的。
输出文本修改器
本页包含 nftables 在使用命令行界面 nft 时支持的几种输出文本修改器的信息。
一般来说,使用 nft –help 或阅读 manpage nft(8) 可以查看所有输出修饰符。
-n, numeric Print fully numerical output.
-s, stateless Omit stateful information of ruleset.
-N, reversedns Translate IP addresses to names.
-S, service Translate ports to service names as described in /etc/services.
-a, handle Output rule handle.
-j, json Format output in JSON
-u, guid Print UID/GID as defined in /etc/passwd and /etc/group.
-y, numeric-priority Print chain priority numerically.
-p, numeric-protocol Print layer 4 protocols numerically.
-T, numeric-time Print time values numerically.
-t, terse Omit contents of sets.
默认输出会以数字形式打印某些信息,而对于众所周知的名称(如 icmp 类型、conntrack 状态、链优先级等),则会使用字符串代替。此外,还会打印计数器值和集合元素等状态信息。
# nft list ruleset
table inet filter {
set s {
type inet_service
elements = { 80, 443 }
}
chain input {
type filter hook input priority filter; policy accept;
counter packets 4447 bytes 1619415
iif "lo" counter packets 337 bytes 25076 accept
ct state established,related counter packets 44899 bytes 106405802 accept
ip6 nexthdr ipv6-icmp icmpv6 type { nd-router-advert, nd-neighbor-solicit, nd-neighbor-advert } counter packets 1 bytes 72 accept
tcp dport 22 drop
ip saddr 8.8.8.8 drop
}
}
翻译修饰语
将各种值转换为文本等价物,或者反过来。我们可以将端口、DNS 名称、服务名称、UID/GID 等分组。
这些选项可以随意组合。下面的示例显示了服务名称(而不是整数)、链优先级值(而不是众所周知的字符串)、连接轨道/协议编号和常量(而不是众所周知的字符串),并显示了反向 DNS 名称(而不是数字 IP 地址):
% nft -nNSy list ruleset
table inet filter {
set s {
type inet_service
elements = { "http", "https" }
}
chain input {
type filter hook input priority 0; policy accept;
iif "lo" counter packets 365 bytes 27092 accept
ct state 0x2,0x4 counter packets 48535 bytes 142472901 accept
ip6 nexthdr 58 icmpv6 type { 134, 135, 136 } counter packets 1 bytes 72 accept
ip saddr dns.google counter packets 0 bytes 0
tcp dport "ssh" accept
}
}
请注意,在生成输出时,翻译某些元素可能需要额外的操作时间。例如,将 IP 地址转换为名称需要查询 DNS 服务器,这对于大型规则集来说可能非常缓慢(因此默认情况下禁用)。
操作和解析修饰符
这些修改器可添加或删除规则集的相关信息,通常在解析输出或执行相关操作时非常有用。
您可以显示不带状态信息(例如不带计数器值)、带句柄和不带集合内容的规则集:
nft -sta list ruleset
table inet filter { # handle 5
set s { # handle 9
type inet_service
}
chain input { # handle 1
type filter hook input priority filter; policy accept;
iif "lo" counter accept # handle 3
ct state established,related counter accept # handle 4
ip6 nexthdr ipv6-icmp icmpv6 type { nd-router-advert, nd-neighbor-solicit, nd-neighbor-advert } counter accept # handle 5
ip saddr 8.8.8.8 counter # handle 8
tcp dport 22 accept # handle 10
}
}
特别值得一提的是规则集的 JSON 表示法。JSON 将以单行方式打印。这里我们使用 perl 的 json_pp 工具来格式化 JSON:
nft -j list ruleset | json_pp
{
"nftables" : [
{
"metainfo" : {
"json_schema_version" : 1,
"release_name" : "Capital Idea #2",
"version" : "0.9.6"
}
},
{
"table" : {
"family" : "inet",
"handle" : 5,
"name" : "filter"
}
},
{
"set" : {
"elem" : [
80,
443
],
"family" : "inet",
"handle" : 9,
"name" : "s",
"table" : "filter",
"type" : "inet_service"
}
},
{
"chain" : {
"family" : "inet",
"handle" : 1,
"hook" : "input",
"name" : "input",
"policy" : "accept",
"prio" : 0,
"table" : "filter",
"type" : "filter"
}
},
{
"rule" : {
"chain" : "input",
"expr" : [
{
"counter" : {
"bytes" : 37707381,
"packets" : 8062
}
}
],
"family" : "inet",
"handle" : 7,
"table" : "filter"
}
},
[..]
Expressions:匹配数据包
匹配数据包元信息
元选择器允许你匹配–在某些情况下还可以设置–数据包元信息。也就是说,本地主机所掌握的有关数据包的信息(如数据包接收的方式和时间)并不一定包含在数据包本身中。
1. 根据数据包信息匹配
以下元选择器根据数据包本身携带的信息匹配数据包:
2. 通过接口匹配
以下元选择器根据传入或传出接口匹配数据包:
使用 iifname 接受进入环回伪设备 lo 的所有流量的规则示例:
# nft add rule filter input meta iifname lo accept
3. 根据数据包标记、路由类别和域进行匹配
您可以使用以下规则匹配标记为 123 的数据包:
# nft add rule filter output meta mark 123 counter
自 nftables v0.7 版起,您可以匹配数据包优先级和 tc classid:
# nft add rule filter forward meta priority abcd:1234未设置优先级的数据包可使用元优先级匹配 无
# nft add rule filter forward meta priority none
4. 根据套接字 UID / GID 匹配
您可以使用用户名来匹配流量,例如
# nft add rule filter output meta skuid pablo counter
或 32 位无符号整数 (UID),以防 /etc/passwd 中没有指定用户的条目。
# nft add rule filter output meta skuid 1000 counter
让我们生成一些 HTTP 流量来测试这条规则:
# wget --spider http://www.google.com
然后,如果检查计数器,就可以验证数据包是否与该规则相匹配。
# nft list table filter
table ip filter {
chain output {
type filter hook output priority 0;
skuid pablo counter packets 7 bytes 510
}
chain input {
type filter hook input priority 0;
}
}
重要提示:使用 ping 测试时要注意,通常安装时会使用 suid,因此流量会与 root 用户(uid=0)相匹配。
5. 通过时间匹配
6. 通过安全选择器匹配
7. 按其他选择器匹配
除上述各小节中的元选择器外,还有以下各种元选择器:
匹配数据包头部
nft 命令行实用程序支持以下第 4 层协议: AH、ESP、UDP、UDPlite、TCP、DCCP、SCTP 和 IPComp。
1. 匹配的以太网标头
您可以根据以太网源地址、目标地址或 EtherType 来匹配数据包:
- ether {saddr | daddr} «ether_addr»
- ether type «ether_type»
如果要匹配目标地址为 ff:ff:ff:ff:ff:ff 的以太网流量,可以键入以下命令:
# nft add rule filter input ether daddr ff:ff:ff:ff:ff:ff counter
您还可以根据 IEEE 802.1Q VLAN 字段(如果存在)匹配数据包:
- vlan 类型 «ether_type»–总是 802.1Q 的 VLAN
- vlan id «12-bit integer»–匹配 VLAN ID VID
- vlan cfi «1-bit integer»–匹配 DEI,Drop Elible Indigator(以前的 CFI,Canonical Format Indicator)。
- vlan pcp «3-bit integer»–匹配 IEEE P802.1p PCP(优先级代码点
不要忘记,第 2 层报头信息只在输入路径中可用。
2. 匹配 ARP 标头
您可以匹配 ARP 标头:
- arp htype «16-bit integer HTYPE» - 匹配硬件链接协议类型(1 表示以太网)
- arp ptype «ether_type» - 匹配以太类型
- arp hlen «8-bit integer HLEN»–匹配硬件地址长度(八进制数)(以太网为6
- arp plen «8-bit integer PLEN»–以八位位组为单位匹配互联网协议地址长度(IPv4 为 4 个八位位组)
- arp operation «arp_op» - 匹配 ARP 操作
- arp {saddr | daddr } ether «ether_addr» - saddr 匹配 SHA,发送硬件地址;daddr 匹配 THA,目标硬件地址
- arp {saddr | daddr } ip «ipv4_addr» - saddr 匹配 SPA(发送方协议地址);daddr 匹配 TPA(目标方协议地址
3. 匹配 IPv4 标头
您还可以根据 IPv4 源和目标来匹配流量,下面的示例显示了如何对来自 192.168.1.100 并寻址到 192.168.1.1 的所有流量进行核算:
# nft add rule filter input ip saddr 192.168.1.100 ip daddr 192.168.1.1 counter
请注意,由于该规则与输入链相连,因此本地机器必须使用 192.168.1.1 地址,否则将无法看到任何匹配信息;-)。
要过滤第四层协议(如 TCP),可以使用协议关键字:
# nft add rule filter input ip protocol tcp counter
4. 匹配 ICMP 流量
您可以通过以下方式放弃所有 ICMP echo 请求(俗称 ping):
# nft add rule filter input icmp type echo-request counter drop
您可以使用 nft describe 查找 nft 可用的 icmp 类型关键字:
# nft describe icmp type
payload expression, datatype icmp_type (ICMP type) (basetype integer), 8 bits
pre-defined symbolic constants (in decimal):
echo-reply 0
destination-unreachable 3
source-quench 4
redirect 5
echo-request 8
router-advertisement 9
router-solicitation 10
time-exceeded 11
parameter-problem 12
timestamp-request 13
timestamp-reply 14
info-request 15
info-reply 16
address-mask-request 17
address-mask-reply 18
您还可以通过匹配单个 icmp 代码来获得更具体的信息:
# nft describe icmp code
payload expression, datatype icmp_code (icmp code) (basetype integer), 8 bits
pre-defined symbolic constants (in decimal):
net-unreachable 0
host-unreachable 1
prot-unreachable 2
port-unreachable 3
net-prohibited 9
host-prohibited 10
admin-prohibited 13
frag-needed 4
# nft add rule filter output icmp code frag-needed counter accept
5. 匹配 IPv6 标头
如果要对寻址为 abcd::100 的 IPv6 流量进行帐户管理,可以键入以下命令:
# nft add rule filter output ip6 daddr abcd::100 counter
不要忘记创建一个 ip6 表,并注册相应的链来运行示例。
要过滤 TCP 等第 4 层协议,可以匹配 IPv6 报头的 nexthdr 字段:
# nft add rule filter input ip6 nexthdr tcp counter
注意:使用 ip6 nexthdr 时,该值仅指下一个报头,即 ip6 nexthdr tcp 仅在 ipv6 数据包不包含任何扩展报头时才会匹配。具体地说,使用 ip6 nexthdr 匹配 IPv6 ICMP 可能会因为引用 RFC2710 而中断:
MLD message types are a subset of the set of ICMPv6 messages, and MLD messages
are identified in IPv6 packets by a preceding Next Header value of 58.
All MLD messages described in this document are sent with a link-local IPv6
Source Address, an IPv6 Hop Limit of 1, and an IPv6 Router Alert option
[RTR-ALERT] in a Hop-by-Hop Options header.
MLD 报文类型是 ICMPv6 报文集合的一个子集,MLD 报文在 IPv6 数据包中通过前面的下一报文头值 58 来识别。
本文档中描述的所有 MLD 报文在发送时都使用链路本地 IPv6 源地址、IPv6 跳数限制 1 和逐跳选项报头中的 IPv6 路由器警报选项 [RTR-ALERT]。
逐跳扩展报头位于 IPv6 报头和 ICMPv6 报头之间,因此在这种情况下,nexthdr 字段显示 58。
您可以使用 meta l4proto 来匹配传输协议(即 TCP、UDP、ICMPv6……),这样就可以在报头中找到真正的传输协议。
如果你特别想匹配 ICMPv6 类型,那么 nftables 会创建一个隐含的 meta l4proto 依赖关系,但不会显示出来,因此你就没必要在注释中写得太详细,即:“如果你想匹配 ICMPv6 类型,那么 nftables 会创建一个隐含的 meta l4proto 依赖关系,但不会显示出来。
# nft add rule filter input icmpv6 type { nd-neighbor-solicit, nd-router-advert, nd-neighbor-advert } accept
可以很好地接受所有 ICMPv6 流量,而不考虑任何可能的扩展头。
注意:目前还不支持混合 IPv6/IPv4 符号的语法:":fffff:192.168.1.0”。
6. 匹配传输协议
下面的规则显示了如何匹配任何类型的 TCP 流量:
# nft add rule filter output ip protocol tcp
如果使用的是 inet 系列,则使用 meta l4proto:
# nft add rule inet filter output meta l4proto tcp
这样,无论数据包是 IPv4 还是 IPv6,都能根据传输协议进行匹配。对于 IPv6,meta l4proto 还会跳过任何扩展头,直到找到第一个传输协议。
7. 匹配 TCP/UDP/UDPlite 流量
下面的示例展示了如何丢弃低 TCP 端口(1-1024)的所有 TCP 流量:
# nft add rule filter input tcp dport 1-1024 counter drop
请注意,该规则使用的是区间(从 1 到 1024)。
要匹配 TCP 标志,需要使用二进制操作。例如,计算非 SYN 数据包:
# nft add rule filter input tcp flags != syn counter
还可以使用更复杂的过滤器。例如,对设置了 SYN 和 ACK 标志的 TCP 数据包进行计数和记录:
# nft -i
nft> add rule filter output tcp flags & (syn | ack) == syn | ack counter log
此示例会丢弃 MSS 低于 500 的 TCP SYN 数据包:
# nft add rule inet filter input tcp flags syn tcp option maxseg size 1-500 drop
8. 在同一规则中匹配 UDP/TCP 标头
下面的示例使用匿名 l4proto 设置和 th(传输头)表达式来匹配指向 53 端口(DNS)的 TCP 和 UDP 数据包:
# nft add rule filter input meta l4proto { tcp, udp } th dport 53 counter packets 0 bytes 0 accept comment \"accept DNS\"
注意:在 nftables 0.9.2 和 Linux 内核 5.3 之前,th 表达式不可用。在这种情况下,您可以使用原始有效载荷表达式来完成相同的工作:
# nft add rule filter input meta l4proto { tcp, udp } @th,16,16 53 counter packets 0 bytes 0 accept comment \"accept DNS\"
匹配连接跟踪状态元信息
nftables conntrack (ct) 表达式通过匹配与 netfilter 连接跟踪系统跟踪的连接相对应的数据包来启用有状态防火墙。
1. 可用的 Conntrack 元数据
参考 conntrack 数据类型非常有用。
1.1 Conntrack 分配的元数据
Conntrack 本身为每个跟踪连接维护大部分元数据。通过 conntrack 命令行工具,可以轻松列出这些元数据并管理连接。以下是部分输出示例,在一台提供活动 sshd 会话的主机上运行。id 选项在输出中包含唯一的 conntrack id;扩展选项以 /proc/net/nf_conntrack 格式生成列表。
conntrack -L -o id,extended
...
ipv4 2 tcp 6 421957 ESTABLISHED src=192.168.0.2 dst=192.168.0.8 sport=34621 dport=22 src=192.168.0.8 dst=192.168.0.2 sport=22 dport=34621 [ASSURED] mark=6 use=1 id=2014938051
...
下表列出了上述输出中的每个 conntrack 元数据字段,以及与之匹配的 nftables CT 选择器。
Matching connection tracking stateful metainformation - nftables wiki
1.2 用户指定的元数据
- Conntrack 标记、标签和区域可由用户设置,nftables 随后可根据它们匹配数据包。
- 此外,notrack、ct helper set 和 ct event set 也会影响 Conntrack 和 nftables 的运行。
更多信息,请参阅设置数据包连接跟踪元信息。
2. 匹配的 Conntrack 元数据
2.1 CT 状态 - Conntrack 状态
几乎可以肯定,ct state 表达式是您最常用的表达式。
conntrack 状态可以是以下之一
Matching connection tracking stateful metainformation - nftables wiki
下面的规则集示例展示了如何使用 nftables 部署极其简单的有状态防火墙:
table inet stateful_fw_demo {
chain IN {
type filter hook input priority filter; policy drop;
ct state established,related accept
}
IN 链中的规则接受属于已建立连接的数据包和相关数据包。注意使用以逗号分隔的列表,列出要匹配的连接状态。默认链策略会丢弃所有其他传入数据包。因此,网络中的计算机试图与你的计算机建立新连接的任何尝试都会被阻止。但是,属于您已启动的流量的流量将被接受。
2.2 CT 助手 - 连接跟踪助手
下面的示例展示了如何根据 conntrack 助手来匹配数据包:
# nft add rule filter input ct helper "ftp" counter
2.3 CT STATT - 连接跟踪状态
Nftables 包含(在 /src/ct.c structt_status_tbl 中)对 conntrack 状态位有意义的符号命名常量,如下表所示:
Matching connection tracking stateful metainformation - nftables wiki
匹配单个标记: ct status snat
匹配多个标记:ct status {expected,dnat}
匹配倒置标志: (ct status & dnat) != dnat(请参阅不能在 ct status 中使用 != 。)
2.4 CT MARK - 连接跟踪标记
下面的示例显示了如何根据 conntrack 标记匹配数据包:
# nft add rule filter input ct mark 123 counter
要了解有关连接轨道标记和数据包标记的更多信息,请参阅设置数据包元信息。
2.5 CT 标签
如果已对数据包应用了 conntrack 标签,则可使用此表达式匹配此类数据包。
2.6 CT 区域
与 ct 标签类似,如果已为数据包指定了 conntrack zone,则可使用此表达式匹配此类数据包。您可以选择在此匹配中包含数据包方向:ct [original | reply] zone zone。
2.7 CT 方向
具有原始方向的数据包与此连接的第一个数据包方向相同,例如,与 TCP 连接的原始 SYN 数据包方向相同。回复方向的数据包的传输方向与原始方向相反。
2.8 CT 失效
您可以根据数据包相关连接的过期时间来匹配数据包,例如,ct 过期时间 < 1m30s。
2.9 CT 计数
您可以根据与指定属性匹配的跟踪连接的当前数量进行匹配。请参阅 connlimits。
2.10 CT 数据包
根据与数据包相关联的连接之前穿过的数据包数量进行匹配。如果指定了可选方向,则只计算该方向的数据包。否则,两个方向的数据包都会被计算在内。例如 ct [original | reply] packets < 10000
2.11 CT 字节
根据与数据包相关联的连接之前穿过的总字节数进行匹配。如果指定了可选方向,则只计算该方向的流量。否则,两个方向的流量都会计算在内。例如 ct [original | reply] bytes < 100000
2.12 CT AVGPKT
根据迄今为止在与数据包相关联的连接上看到的平均数据包大小(字节/包)进行匹配。如果指定了可选方向,则只计算该方向的流量。否则,两个方向的流量都会计算在内。例如 ct [original | reply] avgpkt < 100
2.13 CT L3proto - 连接跟踪 L3 协议
匹配与数据包相关联的 conntrack 条目的 L3 协议。您可以选择在此匹配中包含数据包方向: ct [original | reply] l3proto l3_protocol。
2.14 Conntrack L3 源地址或目标地址
该匹配要求同时指定方向和 L3 协议(目前可识别 ip 或 ip6): ct {original | reply} {ip | ip6} {saddr | daddr}
2.15 CT 协议 - 连接跟踪 L4 协议
匹配与数据包相关联的 conntrack 条目的 L4 协议。您可以选择在此匹配中包含数据包方向: ct [original | reply] protocol l4_protocol。
2.16 连接跟踪 L4 协议源地址或目标地址
该匹配需要指定方向: ct {original | reply} {proto-src | proto-dst}
2.17 CT ID
该表达式将匹配与给定 conntrack id 的特定连接相关联的数据包(如 conntrack -L -o id 所示)。您可以选择在此匹配中包含数据包方向:ct [original | reply] id ct_id。
匹配路由信息
从 linux 4.10 和 nftables v0.7 开始,有了新的机制来匹配与数据包和防火墙机器相关的若干路由信息。
netxhop
出站数据包发送到的直接连接 IP 地址,可用于匹配或记账,例如:”……":
# nft add rule filter postrouting ip daddr 192.168.1.0/24 rt nexthop != 192.168.0.1 drop
这将丢弃任何未通过 192.168.0.1 路由的 192.168.1.0/24 流量。
# nft add rule filter postrouting meter acct { rt nexthop timeout 600s counter }
# nft add rule ip6 filter postrouting meter acct { rt nexthop timeout 600s counter }
这些规则计算每个 nexthop 的出站流量。请注意,如果在 10 分钟内未看到该 nexthop 的流量,超时会释放条目。
一般语法为:RT key 运算符表达式,其中
- key: classid, nexthop
- operator:eq、neq、gt、lt、gte、lte、vmap、map
fib
fib 语句可用于根据数据包的源地址或目的地址从路由表中获取输出接口。
这可用于添加反向路径过滤等功能,或在数据包不是来自同一接口时进行丢弃等操作:
# nft add rule x prerouting fib saddr . iif oif eq 0 drop
只接受来自以太的信息:
# nft add rule x prerouting fib saddr . iif oif eq "eth0" accept
接受来自任何有效接口的信息:
# nft add rule x prerouting fib saddr oif accept
还支持查询地址类型,这可用于只接受同一接口中配置的地址数据包,例如:”……":
# nft add rule x prerouting fib daddr . iif type local accept
也可以使用判决映射,例如
nft 'add rule x prerouting fib saddr . mark oif vmap { "eth0" : drop, "ppp0" : accept }'
它获取数据包源地址,并查询路由表中用于向该地址发送数据包的输出接口索引。数据包的目标地址被用作源地址。标记 “语法告诉 fib 表达式在查询 fib 时还应考虑数据包标记。同样,“iif “和 “oif “告诉 fib 在查询时要考虑数据包的输入和输出接口。
一般语法为:fib key data operator expression,其中
- key:saddr、daddr、mark、iif、oif(使用”.)
- data:oif、oifname、(address)type
- operator:eq、neq、vmap、map
速率限制匹配
您可以通过限制来限制流量,也可以按数据包或按字节来限制。
per packet
下面的示例显示了如何接受每秒最多 10 个 ICMP 回声请求数据包:
# nft add rule filter input icmp type echo-request limit rate 10/second accept
该规则匹配低于 10/second 速率的数据包。这些数据包将被接受,因此您需要一条规则来丢弃超过速率限制的数据包–这与上述规则不匹配。
你也可以反过来表达,即
# nft add rule filter input icmp type echo-request limit rate over 10/second drop
在上例中,over 表示规则匹配的数据包超过了速率限制,这些数据包将被丢弃。
per byte
自 Linux 内核 4.3 起,您还可以按字节设置 ratelimit:
# nft add rule filter input limit rate 10 mbytes/second accept
上述规则接受低于 10 mbytes/seconds 速率的流量。
您还可以使用 over 选项来匹配超过速率限制的数据包,例如
# nft add rule filter input limit rate over 10 mbytes/second drop
上述规则会丢弃速率超过每秒 10 MBytes 的数据包。
Burst
您还可以使用突发参数来指示可以超过 ratelimit 的数据包/字节数:
# nft add rule filter input limit rate 10 mbytes/second burst 9000 kbytes accept
这表明您可以超过 9000 kbytes 的 ratelimit。
您也可以将其用于数据包:
# nft add rule filter input icmp type echo-request limit rate 10/second burst 2 packets counter accept
因此,您可以在 2 个数据包中超过速率。
您还可以使用新 netdev 系列中的入口钩子(而不是使用 tc 命令)在规则中使用 limit 表达式进行流量控制。
使用 over 关键字,可以在策略接受链中直观地使用 limit:
# nft add rule netdev filter ingress pkttype broadcast limit rate over 10/second drop
Statements:根据数据包匹配结果采取行动
接受和丢弃数据包
丢弃数据包
您可以使用丢弃选项来丢弃数据包。请注意,丢弃是一个终止操作,因此不能在其后添加任何其他操作。
# nft add rule filter output drop
测试时请注意,您可能会失去任何互联网连接:-)。
接受数据包
接受任何类型流量的简单规则是:
# nft add rule filter output accept
您可以为该规则添加计数器:
# nft add rule filter output counter accept
因此,您可以看到所有流量都被接受:
# nft list table filter
table ip filter {
chain output {
type filter hook output priority 0;
counter packets 1 bytes 84 accept
}
}
拒绝流量
注意:Linux 内核 3.18 开始支持完全拒绝。
以下规则展示了如何拒绝来自网络的任何流量:
# nft add rule filter input reject
如果您未指定任何原因,则会向源头发送一个 ICMP/ICMPv6 端口不可达数据包。
您可以通过 ct 选择器缩小范围,因此这只会拒绝来自本地机器的非本机流量。
# nft add rule filter input ct state new reject
您还可以指定拒绝原因。例如
# nft add rule filter input reject with icmp type host-unreachable
对于 ICMP,可以使用以下拒绝原因:
- net-unreachable: 目标网络不可达
- host-unreachable: 目标主机不可达
- prot-unreachable: 目标地址协议不可达: 目标协议不可达
- port-unreachable: 端口不可达: 目标端口不可达(默认值)
- net-prohibited(禁止网络 行政禁止的网络
- host-prohibited(禁止主机): 主机被行政禁止
- admin-prohibited: 通信被行政禁止
您还可以拒绝 IPv6 流量,并注明拒绝原因,例如
# nft add rule ip6 filter input reject with icmpv6 type no-route
对于 ICMPv6,可以使用以下原因:
- no-route(无路由): 没有到达目的地的路由
- admin-prohibited(管理禁止): 与目的地的通信被行政禁止
- addr-unreachable(地址不可达): 地址不可达
- port-unreachable(端口不可达): 端口不可达
在 inet 系列中,您可以使用一个抽象概念,即所谓的 icmpx,使用单一规则拒绝 IPv4 和 IPv6 流量。例如
# nft add rule inet filter input reject with icmpx type no-route
该规则会以 “net unreachable(网络不可达)“为由拒绝 IPv4 流量,以 “no route(无路由)“为由拒绝 IPv6 流量。映射如下表所示:
| ICMPX REASON | ICMPv6 | ICMPv4 |
|---|---|---|
| admin-prohibited | admin-prohibited | admin-prohibited |
| port-unreachable | port-unreachable | port-unreachable |
| no-route | no-route | net-unreachable |
| host-unreachable | addr-unreachable | host-unreachable |
跳转到链
使用链树结构来构建规则集通常很有益处。为此,您首先需要通过以下途径创建至少一个常规链:
# nft add chain ip filter tcp-chain
上面的示例创建了 tcp-chain,用于添加过滤 tcp 流量的规则,例如
# nft add rule ip filter input ip protocol tcp jump tcp-chain
我们只需在该 tcp 链中添加一条简单的规则,就能计算数据包和字节数:
# nft add rule ip filter tcp-chain counter
列表应显示类似内容:
# nft list table filter
table ip filter {
chain input {
type filter hook input priority 0;
ip protocol tcp jump tcp-chain
}
chain tcp-chain {
counter packets 8 bytes 2020
}
}
计数器应通过产生简单的 TCP 流量来更新。
注意:您只能跳转到常规链。
jump vs goto
请注意 jump 和 goto 之间的区别。
- 如果使用跳转让数据包在另一条链中处理,数据包会在结束后返回到调用规则的链中。
- 但是,如果使用 goto,数据包将在另一个链中处理,但不会返回到调用规则的链中。在这种情况下,应用于数据包的默认策略将是开始处理数据包的原始基本链的默认策略。
跳转示例
数据包是 src=1.1.1.1 dst=2.2.2.2 tcp sport 111 dport 222
table ip filter {
chain input {
type filter hook input priority 0; policy accept;
# this is the 1º matching rule
ip saddr 1.1.1.1 ip daddr 2.2.2.2 tcp sport 111 tcp dport 222 jump other-chain
# this is the 3º matching rule
ip saddr 1.1.1.1 ip daddr 2.2.2.2 tcp sport 111 tcp dport 222 accept
}
chain other-chain {
# this is the 2º matching rule
counter packets 8 bytes 2020
}
}
goto 示例:
数据包是 src=1.1.1.1 dst=2.2.2.2 tcp sport 111 dport 222
table ip filter {
chain input {
type filter hook input priority 0; policy accept;
# this is the 1º matching rule
# default policy 'accept' will be applied after other-chain ends processing
ip saddr 1.1.1.1 ip daddr 2.2.2.2 tcp sport 111 tcp dport 222 goto other-chain
# this rule will never be reached by this packet!
ip saddr 1.1.1.1 ip daddr 2.2.2.2 tcp sport 111 tcp dport 222 accept
}
chain other-chain {
# this is the 2º matching rule
counter packets 8 bytes 2020
}
}
请注意,只允许对常规链执行跳转和 goto 操作。
计数器
计数器既计算数据包总数,也计算自上次重置以来所看到的字节总数。使用 nftables 时,需要为每条需要计数的规则明确指定一个计数器。
1. 匿名计数器
匿名计数器只适用于其中出现的一条规则。下面的示例使用匿名计数器计算路由到本地主机的所有 tcp 流量:
table ip counter_demo {
chain IN {
type filter hook input priority filter; policy drop;
ip protocol tcp counter
}
}
请注意,计数器语句在规则中的位置很重要,因为 nftables 是按从左到右的线性方式对表达式和语句进行求值的。如果将上述规则改为
counter ip protocol tcp
那么路由到主机的每个数据包(不只是 tcp 数据包)都会更新计数器!
2. 命名计数器
2.1 声明和使用命名计数器
您还可以声明命名计数器,这些计数器可以在多个规则中使用,例如
table inet named_counter_demo {
counter cnt_http {
comment "count both http and https packets"
}
counter cnt_smtp {
}
chain IN {
type filter hook input priority filter; policy drop;
tcp dport 25 counter name cnt_smtp
tcp dport 80 counter name cnt_http
tcp dport 443 counter name cnt_http
}
}
上例定义了两个名为 cnt_http 和 cnt_smtp 的计数器,并在规则中使用它们来统计路由到本地主机的 http(s) 和 smtp 数据包。(本例是为了展示在多条规则中使用单个命名计数器的情况;使用匿名集可以轻松合并使用 cnt_http 的两条规则)。可选的注释属性至少需要 nftables 0.9.7 和内核 5.10。
2.2 列出/读取已命名计数器
2.2.1 从 nft 命令行列出命名计数器
nft list [counter | counters](如下所示)返回所选计数器的当前值。
- 列出特定计数器:
# nft list counter inet named_counter_demo cnt_http
- 列出特定表格中的所有计数器:
# nft list counters table inet named_counter_demo
- 列出规则集中的所有计数器:
# nft list counters
2.2.2 从 Python 读取已命名计数器
下面的部分规则集(注意没有基础链)定义了两个已命名的计数器 voip1 和 voip2,并用它们来计算 udp/5160 和 udp/5161 的 VoIP 流量。注释出的规则展示了如何以简单的方式做到这一点,而 FORWARD 链中的最后两条规则则使用 voipcounters 映射做了同样的事情。当端口(映射元素)越多,使用映射的方法就越有优势。
define ipvoipbox=192.168.0.8
table ip filter {
counter voip1 {
}
counter voip2 {
}
map voipcounters {
type inet_service : counter
elements = {
5160 : "voip1",
5161 : "voip2"
}
}
chain FORWARD {
#ip saddr $ipvoipbox udp dport 5160 counter name voip1 comment "counting packets for SIP1"
#ip daddr $ipvoipbox udp dport 5160 counter name voip1 comment "counting packets for SIP1"
#ip saddr $ipvoipbox udp sport 5161 counter name voip2 comment "counting packets for SIP2"
#ip daddr $ipvoipbox udp dport 5161 counter name voip2 comment "counting packets for SIP2"
ip saddr $ipvoipbox counter name udp sport map @voipcounters
ip daddr $ipvoipbox counter name udp dport map @voipcounters
}
}
我们可以使用 libnftables 库从 Python 中读取当前计数器的值:
from nftables import Nftables
from nftables import json
def getCounter(countername, family='ip'):
nft = Nftables()
nft.set_json_output(True)
_, output, _ = nft.cmd(f"list counter {family} filter {countername}")
j = json.loads(output)
return j['nftables'][1]["counter"]["bytes"]
print(getCounter('voip1'), 'bytes')
print(getCounter('voip2'), 'bytes')
2.3 重置命名计数器
重置计数器会转储当前数据包和字节计数,然后将计数重置为初始值。
- 重置特定计数器:
# nft reset counter inet named_counter_demo cnt_http
- 重置特定表格中的所有计数器:
# nft reset counters table inet named_counter_demo
- 重置规则集中的所有计数器:
# nft reset counters
注意:重置计数器不会重置匿名计数器,请参见 bug #1401。实现这一目的的变通方法是恢复当前规则集,并删除所有有状态信息:
(echo "flush ruleset"; nft --stateless list ruleset) | nft -f -
显然,这会删除所有状态,因此可能会产生不希望看到的副作用,例如重置配额。
记录流量日志
注意:Linux 内核 3.17 开始提供完整的日志记录支持。如果运行的是旧版内核,则必须使用 modprobe ipt_LOG 才能启用日志记录功能。
可以使用日志操作记录数据包。记录所有传入流量的最简单规则是
# nft add rule filter input log
一个典型的匹配、记录和接受传入 ssh 流量的规则如下:
# nft add rule filter input tcp dport 22 ct state new log prefix \"New SSH connection: \" accept
前缀表示用作日志信息前缀的初始字符串。
请注意,nftables 允许在一条规则中执行两个操作,而iptables 则需要两条规则。
还要注意的是,规则是从左向右评估的。因此下面的规则
# nft add rule filter input iif lo log tcp dport 22 accept
将记录 lo 接口上的所有数据包,而不仅仅是目标端口为 22 的数据包。
向用户空间排队发送日志 与 iptables 一样,您可以使用现有的 nflog 基础设施将日志信息发送到 ulogd 或基于 libnetfilter_log 的自定义用户空间应用程序。
为此,您只需指明 nflog 组:
# nft add rule filter input tcp dport 22 ct state new log prefix \"New SSH connection: \" group 0 accept
然后,运行示例测试程序:
libnetfilter_log/utils% ./nfulnl_test
然后你就能看到每个新 ssh 连接的日志信息了。
日志标记 自 nftables v0.7 起,支持日志标记。
启用 TCP 序列和选项日志:
# nft add rule x y log flags tcp sequence,options
启用 IP 选项:
# nft add rule x y log flags ip options
启用套接字 UID:
# nft add rule x y log flags skuid
启用以太网链路层地址:
# nft add rule x y log flags ether
启用所有标记:
# nft add rule x y log flags all
其他选项 还有一些附加选项,可在不同情况下对日志记录进行微调:
- level: 日志记录的 Syslog 级别,由以下值组成:emerg、alert、critical、err、warn [默认]、notice、info、debug
- snaplen: 要包含在网链信息中的数据包有效载荷长度(无符号整数,32 位)
- queue-threshold:队列阈值: 如果向用户空间发送队列日志,则在向用户空间发送前要在内核中排队的数据包数量(无符号整数,32 位)
在下面的示例中,队列阈值参数用于提高 ulogd2 守护进程在用户空间的性能:
# nft add rule filter forward ct state invalid log queue-threshold 20 prefix "ct_invalid" group 0 drop
执行网络地址转换(NAT)
nat 链类型允许执行 NAT。这种链类型具有特殊的语义:
- 流量的第一个数据包将用于查找匹配规则,该规则将为该流量设置 NAT 绑定。这也会相应地处理第一个数据包。
- 数据流中的后续数据包不需要查找规则:NAT 引擎使用第一个数据包已经设置的 NAT 绑定信息来执行数据包操作。
在过滤类型链中添加 NAT 规则会导致错误。
1. 有状态 NAT
有状态 NAT 需要 nf_conntrack 内核引擎来匹配/设置数据包的有状态信息,并根据连接状态进行操作。这是最常见的 NAT 执行方式,也是我们建议您采用的方法。
请注意,在 4.18 之前的内核版本中,即使没有任何规则,也必须注册预路由/后向路由链,因为这些链将调用 NAT 引擎处理来自回复方向的数据包。本文中的其余文档假定较新的内核不再需要这种不便。
1.1 源 NAT
如果要对从局域网流向互联网的流量进行源 NAT,可以创建一个带有后路由链的新表 nat:
# nft add table nat
# nft 'add chain nat postrouting { type nat hook postrouting priority 100 ; }'
然后,添加以下规则:
# nft add rule nat postrouting ip saddr 192.168.1.0/24 oif eth0 snat to 1.2.3.4
该规则匹配从 192.168.1.0/24 网络到接口 eth0 的所有流量。IPv4 地址 1.2.3.4 被用作匹配此规则的数据包的源地址。
1.1.1 NAT 池
可以指定源 NAT 池:
# nft add rule inet nat postrouting snat ip to 10.0.0.2/31
# nft add rule inet nat postrouting snat ip to 10.0.0.4-10.0.0.127
使用传输协议源端口映射:
# nft add rule inet nat postrouting ip protocol tcp snat ip to 10.0.0.1-10.0.0.100:3000-4000
1.2 目的地 NAT
您需要添加以下表格和链配置:
# nft add table nat
# nft 'add chain nat prerouting { type nat hook prerouting priority -100; }'
然后,您可以添加以下规则:
# nft 'add rule nat prerouting iif eth0 tcp dport { 80, 443 } dnat to 192.168.1.120'
这会将 TCP 端口 80 和 443 的传入流量重定向到 192.168.1.120。
1.3 伪装
注意:从 Linux 内核 3.18 开始可使用 masquerade。
伪装是 SNAT 的一种特殊情况,源地址会自动设置为输出接口的地址。例如
# nft add rule nat postrouting masquerade
请注意,伪装只对 NAT 类型的后路由链有意义。
1.4 重定向
注意:重定向从 Linux 内核 3.19 开始可用。
使用重定向后,数据包将被转发到本地机器。重定向是 DNAT 的一种特殊情况,其目的地是当前机器。
# nft add rule nat prerouting redirect
此示例将 22/tcp 流量重定向到 2222/tcp:
# nft add rule nat prerouting tcp dport 22 redirect to 2222
该示例将 53/tcp 流量重定向到监听端口 10053/tcp 的本地代理:
# nft add rule nat output tcp dport 853 redirect to 10053
请注意:重定向只适用于 NAT 类型的预路由和输出链。
1.5 NAT 标志
自 Linux 内核 3.18 起,您可以将以下标记与 NAT 语句结合使用:
- random:随机化源端口映射。
- fully-random:完全随机化端口。
- persistent: 为客户端的每个连接提供相同的源地址/目标地址。
例如
# nft add rule nat postrouting masquerade random,persistent
# nft add rule nat postrouting ip saddr 192.168.1.0/24 oif eth0 snat to 1.2.3.4 fully-random
1.6 inet family NAT
自 Linux 内核 5.2 起,支持在 inet 系列链中执行有状态 NAT。语法和语义等同于 ip/ip6 族;唯一的例外是,如果指定了 IP 地址,则需要使用 ip 或 ip6 前缀来明确地址族:
# nft add rule inet nat prerouting dnat ip to 10.0.0.2
# nft add rule inet nat prerouting dnat ip6 to feed::c0fe
1.7 不兼容问题
在内核 4.18 之前,无法同时使用 iptables 和 nft 执行 NAT。因此,请确保已卸载 iptable_nat 模块:
rmmod iptable_nat
在以后的内核中,可以同时使用 iptables 和 nftables nat。nat 链根据优先级进行查询,第一个添加 nat 映射(dnat、snat、masquerade)的匹配规则将用于连接。
2. 无状态 NAT
这种类型的 NAT 只根据规则修改每个数据包,而不跟踪任何其他状态/连接。这对 1:1 映射有效,而且比有状态 NAT 更快。不过,这也很容易自食其果。如果你的环境不需要这种方法,最好坚持使用有状态 NAT。
你必须禁止对修改后的数据包进行连接跟踪。这可以通过在规则中加入 notrack 关键字来实现。这样做会给数据包附加一个模板连接跟踪条目,指示 conntrack 核心不要在 conntrack 表中初始化新条目。必须使用优先级为原始或更低的钩子。否则,notrack 将不会在查询 conntrack 表之前得到处理。
下面的规则集演示了如何重写每个数据包的目标 IP 和端口(也包括 IPv6)。请注意,这些规则会影响到达所有接口的所有 TCP 数据包,仅用于演示目的。
table inet raw {
chain prerouting {
type filter hook prerouting priority raw; policy accept;
ip protocol tcp ip daddr set 192.168.1.100 tcp dport set 10 notrack
ip6 nexthdr tcp ip6 daddr set fe00::1 tcp dport set 10 notrack
}
}
请务必查看我们有关混淆数据包和设置数据包连接跟踪元信息的文档。
要使用此功能,您需要 nftables >=0.7 和 linux kernel >= 4.9。
设置数据包元信息
您可以在数据包中设置一些元信息。请注意,使用这些功能需要 Linux 内核 >= 3.14。
1. 数据包标记
下面的示例显示了如何设置数据包标记:
# nft add rule route output mark set 123
2. 数据包标记和连接器标记
您可以像在 iptables 中一样保存/恢复 conntrack 标记。
在本例中,nf_tables 引擎将数据包标记设为 1。 在最后一条规则中,该标记被保存在与数据流相关联的 conntrack 条目中:
# nft add rule filter forward meta mark set 1
# nft add rule filter forward ct mark set mark
在本例中,数据包中存储了 conntrack 标记。
# nft add rule filter forward meta mark set ct mark
3. 数据包秒标记
- 您可以使用 secmark 对象为数据包设置 SECMARK 标签。
- nftables 0.9.3 中的新功能是通过关联的 conntrack secmark 设置数据包的 secmark:
meta secmark set ct secmark
4. 数据包优先级
您可以设置数据包的优先级。
本例显示了与 iptables 中”-j CLASSIFY “类似的操作:
# nft add table mangle
# nft add chain postrouting {type route hook output priority -150\; }
# nft add rule mangle postrouting tcp sport 80 meta priority set 1
警告: 优先级语法中的一个错误将在 nftables 的后续版本中修复。
5. 数据包类型
您可以设置数据包类型:
meta pkttype set {pkt_type}
6. nftrace
在数据包中设置 nftrace 调试位将报告通过 nf_tables 堆栈的历程:
# nft add rule filter forward udp dport 53 meta nftrace set 1
7. 选项组合
考虑到 nftables 灵活的设计,请记住您可以在一条规则中对数据包执行多种操作:
# nft add rule filter forward ip saddr 192.168.1.1 meta nftrace set 1 meta priority set 2 meta mark set 123
设置数据包连接跟踪元信息
您可以设置数据包连接轨迹元信息的某些位,也可以对其进行匹配。
1. notrack - 绕过连接跟踪
您可以使用 notrack 语句(在 Linux 内核 4.9 和 nftables 0.7 中添加)明确跳过匹配数据包的连接跟踪。要使 notrack 规则有效,必须在 conntrack 被触发之前使用。将其附加到带有预路由钩子且优先级 < NF_IP_PRI_CONNTRACK (-200) 的基本链上,就能确保这一点。使用原始优先级 (-300) 也是一个不错的选择。下面的示例跳过了进入 tcp 端口 80(http)和 443(https)的流量:
# nft add table my_table
# nft add chain my_table prerouting { type filter hook prerouting priority -300 \; }
# nft add rule my_table prerouting tcp dport { 80, 443 } notrack
2. ct helper set - 指定 conntrack 助手
您可以为每个数据包分配一个 conntrack 辅助器。
使用命名对象实例化一个辅助器:
table filter {
ct helper sip-5060 {
type "sip" protocol udp;
}
ct helper tftp-69 {
type "tftp" protocol udp;
}
ct helper ftp-standard {
type "ftp" protocol tcp;
}
chain c {
type filter hook prerouting priority 0;
}
}
您的链优先级必须大于 -200,因为 conntrack 会在此优先级注册。否则,数据包将找不到任何 conntrack 信息(这是附加辅助程序所必需的)。
然后,从规则中
# nft add rule filter c ct state new tcp dport 21 ct helper set "ftp-standard"
# nft add rule filter c ct state new udp dport 5060 ct helper set "sip-5060"
# nft add rule filter c ct state new udp dport 69 ct helper set "tftp-69"
您可以使用map,用一条规则分配多个助手:
nft add rule filter c ct state new ct helper set ip protocol . th dport map { \
udp . 69 : "tftp-69", \
udp . 5060 : "sip-5060", \
tcp . 21 : "ftp-standard" }
会根据传输协议号和传输目标端口设置助手。
使用此功能需要 nftables >= 0.8 和内核 >= 4.12。
如果使用的是旧版本的 nftables,可以通过以下方式启用自动分配:
# echo 1 > /proc/sys/net/netfilter/nf_conntrack_helper
此外,还可以使用 sysctl 参数:
net.netfilter.nf_conntrack_helper = 1
3. ct 超时设置 - 设置 conntrack 超时策略
4. CT 预期设置 - 创建 conntrack 预期
5. CT 标记设置 - 设置 conntrack 标记
在 conntrack 中保存数据包 nfmark:
ct mark set meta mark
6. CT 标签设置 - 设置连接跟踪标签
Conntrack 标签是 128 位的比特字段。
7. CT 区域设置 - 设置连通轨道区域
在设置 conntrack 区域时,必须在数据包被 conntrack 接收之前进行设置。下面的演示规则集使用原始优先级链中的 ct 区域设置规则来实现这一目的:
table inet zone_demo {
chain PRE {
type filter hook prerouting priority raw;
iif eth3 ct zone set 23
}
chain OUT {
type filter hook output priority raw;
oif eth3 ct zone set 23
}
}
8. CT secmark 设置 - 根据数据包 secmark 设置连接跟踪 secmark
nftables 0.9.3 中的新功能,可通过数据包秒标记在连接跟踪条目上设置秒标记:
ct secmark set meta secmark
注意:您不能将ct secmark 设置为常量值,必须如上所述从匹配的数据包中进行设置。
9. ct 事件设置 - 设置 conntrack 事件
限制 ctnetlink 报告的事件:
ct event set new,related,destroy
篡改数据包标题(包括无状态 NAT)
自 nft v0.6 起,nftables 支持数据包头混杂,包括无状态 NAT。
注意:如果要混淆包含在第 4 层校验和伪报头中的数据包字段,则需要 Linux 内核版本 >= 4.10。
要对数据包头部字段进行混淆,应创建一条规则来匹配数据包,匹配所需的头部字段并为其设置一个新值:
# nft add table raw
# nft add chain raw prerouting {type filter hook prerouting priority -300\;}
# nft add rule raw prerouting tcp dport 8080 tcp dport set 80
上述命令创建了一个名为 raw 的表、一个名为 prerouting 的链(请参阅 Netfilter 钩子)和一条将 TCP 数据包的目标端口从 8080 改为 80 的规则。
篡改 TCP 选项 自 Linux 内核 4.14 和 nftables 0.9 起,您可以将 TCP MSS 与路径 MTU 绑定。这在路由器通过 PPPoE 封装流量的情况下非常方便,许多 DSL(和一些 FTTH)提供商就是这么做的:
# nft add rule ip filter forward tcp flags syn tcp option maxseg size set rt mtu
其中 rt mtu 在运行时根据路由缓存通过路径 MTU 发现(PMTUD)观察到的情况计算 MTU。
注:TCP 最大网段大小通过原始 syn 和回复 syn+ack 数据包中的 TCP 选项公布。TCP 最大网段大小不是协商确定的,RFC 规定在流量的每个方向都可以有不同的 TCP 最大网段大小。因此,请确保对原始 syn 包和回复 syn+ack 包的 TCP 选项都进行了更改。
iptables 用户注意:“tcp option maxseg size set rt mtu “等同于”-j TCPMSS –clamp-mss-to-pmtu” 。
您也可以手动设置为固定值,例如,PPPoE 封装数据包需要 8 个字节,因此,假设 MTU 为 1500 字节,则 1500 - 20(IPv4 头)- 20(TCP 头)- 8(PPPoE 头)= 1452 字节:
# nft add rule ip filter forward tcp flags syn tcp option maxseg size set 1452
其他支持的 TCP 选项包括:窗口、允许卸载、卸载、时间戳和 eol。
与 conntrack 的交互 请注意与 conntrack 的交互,必须取消对流量的跟踪。您可以在一条规则中做到这一点:
# nft add rule ip6 raw prerouting ip6 daddr fd00::1 ip6 daddr set fd00::2 notrack
有关要篡改的数据包头的更多信息,请查看 manpage nft(8)、Matching packet headers 和 Quick reference-nftables in 10 minutes。
复制数据包
自 Linux 内核 4.3 起,您可以将数据包复制到另一个 IPv4 或 IPv6 目标地址。您可能希望使用此功能将选定的流量从本地系统复制到远程主机,以便进一步检查。
以下规则将所有流量复制到 172.20.0.2:
# nft add rule mangle prerouting dup to 172.20.0.2
您还可以强制 dup 语句使用指定设备路由流量:
# nft add rule mangle prerouting dup to 172.20.0.2 device eth1
上述规则规定,重复数据包必须通过 eth1 接口离开系统。您的系统必须有一条通过 eth1 抵达 172.20.0.2 的路由,这样才能起作用。
您还可以将 dup 语句与映射相结合。例如
# nft add rule mangle prerouting dup to ip saddr map { 192.168.0.1 : 172.20.0.2, 192.168.0.1 : 172.20.0.3 }
该规则会根据源 IPv4 地址向不同的远程主机发送重复数据包。
负载平衡
自 nftables v0.7 版起,NAT 负载均衡功能已得到支持。
别忘了特殊的 NAT 链语义: 只有第一个数据包会评估规则,后续数据包将依靠 conntrack 来应用 NAT 信息。
1. 循环罗盘
该方法使用 nftables 数字生成器。
下面的示例在 192.168.10.100 和 192.168.20.200 之间循环分配新连接。
# nft add rule nat prerouting dnat to numgen inc mod 2 map { \
0 : 192.168.10.100, \
1 : 192.168.20.200 }
您还可以使用间隔来模拟不同后端权重的流量分布:
# nft add rule nat prerouting dnat to numgen inc mod 10 map { \
0-5 : 192.168.10.100, \
6-9 : 192.168.20.200 }
分配也可以基于端口:
# nft add rule nat prerouting ip protocol tcp dnat to 192.168.1.100 : numgen inc mod 2 map {\
0 : 4040 ,\
1 : 4050 }
此外,还支持随机分布和基于概率的分布:
# nft add rule nat prerouting numgen random mod 2 vmap { 0 : jump mychain1, 1 : jump mychain2 }
# nft add rule nat prerouting numgen random mod 100 vmap { 0-49 : jump mychain1, 50-99 : jump mychain2 }
2. 基于哈希值的一致分发
使用 nftables 内部散列机制。
# nft add rule x y dnat to jhash ip saddr . tcp dport mod 2 map { \
0 : 192.168.20.100, \
1 : 192.168.30.100 }
这依赖于 Jenkins 哈希值。
3. 使用无状态 NAT
您还可以通过无状态 NAT 方法来实现负载平衡。您可以将其与循环分配法和基于一致哈希值的分配法相结合。
下面的示例使用了循环流量分配:
# nft add rule t c tcp dport 80 ip daddr set numgen inc mod 2 map { 0 : 192.168.1.100, 1 : 192.168.1.101 }
由于没有流量跟踪,这比有状态 NAT 更轻量级。这确实是在混淆数据包头。
4. 使用直接服务器返回(DSR)
此示例从入口为无连接流量执行 DSR 拓扑:
# nft add rule netdev t c udp dport 53 ether saddr set aa:bb:cc:dd:ff:ee ether daddr set numgen inc mod 2 map { 0 : xx:xx:xx:xx:xx:xx, 1: yy:yy:yy:yy:yy:yy } fwd to eth0
面向连接流的方法如下所示:
# nft add rule netdev t c tcp dport 80 ether saddr set aa:bb:cc:dd:ff:ee ether daddr set jhash ip saddr . tcp sport mod 2 map { 0 : xx:xx:xx:xx:xx:xx, 1: yy:yy:yy:yy:yy:yy } fwd to eth0
请注意,xx:xx:xx:xx:xx:xx:xx 和 yy:yy:yy:yy:yy:yy 需用真正的目标 MAC 地址替换。这也是对数据包头的混淆。
向用户空间排队
基本操作 重要提示:使用 nftables 向用户空间发送数据包需要 Linux 内核 3.14。
像在 iptables 中一样,您可以使用 nfqueue 基础设施向使用 libnetfilter_queue 库的用户空间应用程序发送数据包。
您可以使用示例应用程序进行测试:
libnetfilter_queue/utils% ./nfqnl_test
然后,必须添加规则,将数据包排入用户空间。如果没有指定队列,数据包将被发送到 0 号队列:
# nft add filter input counter queue
然后,当产生一些流量时,你就应该开始看到数据包了:
...
pkt received
hw_protocol=0x0800 hook=1 id=28 hw_src_addr=00:80:48:52:ff:8a indev=3 uid=1000 gid=1000 payload_len=110
entering callback
pkt received
hw_protocol=0x0800 hook=1 id=29 hw_src_addr=00:80:48:52:ff:8a indev=3 uid=1000 gid=1000 payload_len=98
entering callback
...
最多有 65535 个队列。您可以使用以下命令选择不同的队列:
# nft add filter input counter queue num 3
然后,您必须启动测试应用程序,并在参数中指明要监听数据包的队列编号:
libnetfilter_queue/utils% ./nfqnl_test 3
重要提示:如果没有用户空间应用程序监听该队列,那么所有数据包都将被丢弃。
更高级的配置
您还可以启用旁路选项,如果没有应用程序监听队列,该选项将跳过向用户空间的数据包排队。如果没有应用程序在等待数据包,规则就会像接受规则一样运行。
# nft add filter input counter queue num 0 bypass
您还可以将流量负载均衡到多个队列:
# nft add filter input counter queue num 0-3
因此,0 至 3 的队列编号将用于此目的。您可以运行四个nfqnl_test实例来测试。
libnetfilter_queue/utils% ./nfqnl_test 0 &
libnetfilter_queue/utils% ./nfqnl_test 1 &
libnetfilter_queue/utils% ./nfqnl_test 2 &
libnetfilter_queue/utils% ./nfqnl_test 3 &
在进行负载均衡时,可以选择使用fanout选项,将 CPU ID 作为索引,将数据包映射到队列中。这样做的目的是,如果每个 CPU 都有一个队列/用户空间应用程序,就能提高性能:
# nft add filter input counter queue num 0-3 fanout
当然,这些选项可以组合使用,例如,您可以使用
# nft add filter input counter queue num 0-3 fanout,bypass
用于性能数据包分类的高级数据结构
区间
区间以 value-value 表示。
以下规则会丢弃指向 IP 地址区间 192.168.0.1 至 192.168.0.250 的传入流量:
# nft add rule filter input ip daddr 192.168.0.1-192.168.0.250 drop
您可以使用任何类型的常数值间隔。本例使用的是 TCP 端口时间间隔:
# nft add rule filter input tcp ports 1-1024 drop
您也可以使用集合中的区间,下面的示例显示了如何将两个 IP 地址区间列入黑名单:
# nft add rule ip filter input ip saddr { 192.168.1.1-192.168.1.200, 192.168.2.1-192.168.2.200 } drop
在 verdict maps 中,区间的作用方式相同:
# nft add rule ip filter forward ip daddr vmap { 192.168.1.1-192.168.1.200 : jump chain-dmz, 192.168.2.1-192.168.20.250 : jump chain-desktop }
连接
自 Linux 内核 4.1 起,nftables 支持连接。
这项新功能允许你将两个或多个选择器放在一起,在集合、映射、vmaps 和表中执行非常快速的查找。
1. 匿名集
# nft add rule ip filter input ip saddr . ip daddr . ip protocol { 1.1.1.1 . 2.2.2.2 . tcp, 1.1.1.1 . 3.3.3.3 . udp} counter accept
因此,如果数据包的源 IP 地址、目标 IP 地址和第 4 级协议匹配:
- 1.1.1.1 和 2.2.2.2 以及 TCP。 或
- 1.1.1.1 和 3.3.3.3 和 UDP。
nftables 会更新该规则的计数器,然后接受数据包。
2. 命名 verdict maps
下面的示例使用两个选择器的连接创建了白名单 vmap:
# nft add map filter whitelist { type ipv4_addr . inet_service : verdict \; }
创建 vmap 后,可以通过创建以下连接的规则来使用它:
# nft add rule filter input ip saddr . tcp dport vmap @whitelist
上述规则根据源 IP 地址和 TCP 目的地端口查找判定。
判决图最初是空的。您可以用元素动态填充它:
# nft add element filter whitelist { 1.2.3.4 . 22 : accept}
在声明连接时,可以使用通用集合选项,如 typeof 关键字和计数器功能:
table inet fmytable {
set myset {
typeof ip daddr . tcp dport
counter
elements = { 1.1.1.4 . 22 counter packets 0 bytes 0,
1.1.1.5 . 23 counter packets 0 bytes 0,
1.1.1.6 . 24 counter packets 0 bytes 0 }
}
}
3. 匿名 maps
下面的规则根据以下因素确定用于对数据包执行 DNAT 的目标 IP 地址:
- 源 IP 地址 和
- 目标 TCP 端口
# nft add rule ip nat prerouting dnat to ip saddr . tcp dport map { 1.1.1.1 . 80 : 192.168.1.100, 2.2.2.2 . 8888 : 192.168.1.101 }
4. 示例
一些具体的连接示例,让你了解这项新功能有多强大。
4.1 网络地址
下面的示例在每个元素中使用网络掩码实现了一个 vmap:
table inet mytable {
set myset {
type ipv4_addr . ipv4_addr
flags interval
elements = { 192.168.0.0/16 . 172.16.0.0/25,
10.0.0.0/30 . 192.168.1.0/24,
}
}
chain mychain {
ip saddr . ip daddr @myset counter accept
}
}
注意:在 Linux 内核 5.6 和 nftables 0.9.4 之前,CIDR 符号不可用,您需要使用变通方法:
# nft add rule tablename chainname ip saddr and 255.255.255.0 . ip daddr and 255.255.255.0 vmap { 10.10.10.0 . 10.10.20.0 : accept }
请注意,这不是一个区间,而是屏蔽 ip saddr 和 ip daddr,然后将两个结果连接起来。该连接用于在 vmaps 中查找与该结果匹配的地址。这种语法可能会在未来版本中进行压缩,以支持 CIDR 符号。
使用命名映射也可以轻松实现这一功能:
# nft add map tablename myMap { type ipv4_addr . ipv4_addr : verdict \; }
# nft add rule tablename chainname ip saddr and 255.255.255.0 . ip saddr and 255.255.255.0 vmap @myMap
# nft add element tablename myMap { 10.10.10.0 . 10.10.20.0 : accept }
4.2 接口
下面的示例同时检查了转发数据包的输入和输出接口。
# nft add rule tablename chainname iif . oif vmap { eth0 . eth1 : accept }
4.3 某些 ipset 类型
这些 ipset 类型可以在 nftables 中使用连接来实现。可能存在更多的等价关系,这只是数据类型组合的问题。当然,你也可以用命名的映射/集合来实现这些类型。
请参阅从 ipset 到 nftables 页面中的示例。
数学运算
nftables 包含一些有趣的数学运算生成器,可用于执行负载平衡等高级操作。
数字生成器 数字生成器语句有以下选项:
- type:inc/random
- modulus(模数):最大值
- offset:从哪个值开始计算
一些向数据包分配标记的示例:
table ip t {
chain c {
mark set numgen inc mod 4 offset 3
mark set numgen random mod 50 offset 20
mark set numgen inc mod 100
}
}
语句 numgen inc mod 2 offset 100 将生成一系列数字,如 100、101、100、101……。
散列 nftables 支持任意密钥组合的散列:
table ip t {
chain c {
mark set jhash ip saddr mod 2
mark set jhash ip saddr . tcp dport mod 2
mark set jhash ip saddr . tcp dport . iiftype mod 2
}
}
有状态对象
计数器
定额
限制
连接限制(ct计数)
其他对象
Conntrack 辅助器(ct 辅助器,第 7 层 ALG)
Conntrack 超时策略(ct timeout)
Conntrack 期望(ct expectation)
同步代理
Secmarks
通用集基础设施
集合
元素超时
从数据包路径更新数据集
映射
判定映射
计量(在 nftables 0.8.1 之前称为流量表)
流量表(fastpath 网络协议栈旁路)
Examples
工作站的简单规则集
服务器的简单规则集
家用路由器的简单规则集
网桥过滤
使用 nftables 映射的多重 NAT
经典周边防火墙示例
端口锁定示例
tc 结构分类示例
使用配置管理系统(如 puppet、ansible 等)
地理 IP 匹配
RULESET
{list | flush} ruleset [family]
TABLES
{add | create} table [family] table [ {comment comment ;} { flags 'flags ; }]
{delete | list | flush} table [family] table
list tables [family]
delete table [family] handle handle
CHAINS
{add | create} chain [family] table chain [{ type type hook hook [device device] priority priority ; [policy policy ;] [comment comment ;] }]
{delete | list | flush} chain ['family] table chain
list chains [family]
delete chain [family] table handle handle
rename chain [family] table chain newname
RULES
{add | insert} rule [family] table chain [handle handle | index index] statement ... [comment comment]
replace rule [family] table chain handle handle statement ... [comment comment]
delete rule [family] table chain handle handle
SETS
add set [family] table set { type type | typeof expression ; [flags flags ;] [timeout timeout ;] [gc-interval gc-interval ;] [elements = { element[, ...] } ;] [size size ;] [comment comment ;] [policy 'policy ;] [auto-merge ;] }
{delete | list | flush} set [family] table set
list sets [family]
delete set [family] table handle handle
{add | delete} element [family] table set { element[, ...] }
MAPS
add map [family] table map { type type | typeof expression [flags flags ;] [elements = { element[, ...] } ;] [size size ;] [comment comment ;] [policy 'policy ;] }
{delete | list | flush} map [family] table map
list maps [family]
ELEMENTS
{add | create | delete | get } element [family] table set { ELEMENT[, ...] }
FLOWTABLES
{add | create} flowtable [family] table flowtable { hook hook priority priority ; devices = { device[, ...] } ; }
list flowtables [family]
{delete | list} flowtable [family] table flowtable
delete flowtable [family] table handle handle
LISTING
list { secmarks | synproxys | flow tables | meters | hooks } [family]
list { secmarks | synproxys | flow tables | meters | hooks } table [family] table
list ct { timeout | expectation | helper | helpers } table [family] table
STATEFUL OBJECTS
{add | delete | list | reset} type [family] table object
delete type [family] table handle handle
list counters [family]
list quotas [family]
list limits [family]